SSH offre plusieurs formes d’authentification, telles que par mot de passe
et par clé publique. Cette dernière est considérée comme plus sécurisée.
Cependant, l’authentification par mot de passe reste répandue, notamment avec
les équipements réseau1.
Une solution classique pour éviter de taper un mot de passe à chaque connexion
est sshpass, ou sa variante plus correcte passh. Voici une fonction pour
Zsh, récupérant le mot de passe depuis pass, un gestionnaire de mots de
passe2 :
Cette approche est un peu fragile car elle nécessite d’examiner la sortie de la
commande ssh pour y chercher une invite de mot de passe. De plus, si aucun mot
de passe n’est requis, le gestionnaire de mots de passe est tout de même
invoqué. Depuis OpenSSH 8.4, nous pouvons à la place utiliser SSH_ASKPASS
et SSH_ASKPASS_REQUIRE :
ssh(){set-olocaloptions-olocaltraps
localpassname=network/ssh/password
localhelper=$(mktemp)trap"command rm -f $helper"EXITINT
>$helper<<EOF#!$SHELLpass show $passname | head -1EOFchmodu+x$helperSSH_ASKPASS=$helperSSH_ASKPASS_REQUIRE=forcecommandssh"$@"}
Si le mot de passe est incorrect, nous pouvons afficher une invite de mot de
passe à la seconde tentative :
Une amélioration possible est d’utiliser une entrée de mot de passe différente
en fonction de l’hôte distant3 :
ssh(){# Informations de connexionlocal-Adetails
details=(${=${(M)${:-"${(@f)$(commandssh-G"$@"2>/dev/null)}"}:#(host|hostname|user) *}})localremote=${details[host]:-details[hostname]}locallogin=${details[user]}@${remote}# Nom du mot de passelocalpassname
case"$login"inadmin@*.example.net)passname=company1/ssh/admin;;bernat@*.example.net)passname=company1/ssh/bernat;;backup@*.example.net)passname=company1/ssh/backup;;esac# Sans nom de mot de passe, on se rabat sur ssh[[-z$passname]]&&{# Just regular ssh...commandssh"$@"return$?}# Invocation de SSH avec SSH_ASKPASS# […]}
Il est également possible d’adapter scp pour qu’il utilise notre fonction
ssh :
Le code complet est disponible dans mon zshrc. Il est également possible de
placer le contenu de la fonction ssh() dans un script séparé et de remplacer
command ssh par /usr/bin/ssh pour éviter un appel récursif. Dans ce cas, la
fonction scp() n’est plus nécessaire.
Mise à jour (12.2023)
Cet article a été longuement débattu sur Hacker News.
Tout d’abord, certains constructeurs rendent difficile
l’association d’une clé SSH à un utilisateur. Ensuite, de nombreux
constructeurs ne prennent pas en charge l’authentification basée sur un
certificat, ce qui complique la mise en place à grande échelle. Enfin, les
interactions entre l’authentification par clé publique et des méthodes
d’autorisation plus fines telles que TACACS+ et Radius restent un domaine
inexploré. ↩︎
Le mot de passe en clair n’apparaît jamais sur la ligne de
commande, dans l’environnement ou sur le disque, rendant difficile sa
capture par un tiers non privilégié. Sur Linux, Zsh fournit le mot de
passe via un descripteur de fichier. ↩︎
Pour comprendre la magie noire derrière la quatrième ligne, vous pouvez
vous aider de print -l et de la page de manuel zshexpn(1). details
est un tableau associatif défini à partir d’un tableau
alternant clefs et valeurs. ↩︎
Avec la sortie de Debian 12, en juin dernier, je dois mettre à jour un serveur de dépôts de paquets.
Comme ce serveur contient un seul paquet (imapsync, qui n'est pas dans debian), il a été décidé de supprimer ce serveur de dépôt et de directement passer par le code source amont lorsqu'on a besoin d'utiliser cet outil au boulot.
Je ne me souviens plus de la dernière fois où j'ai utilisé la commande make clean.
Si j'empaquète pour Debian, le travail se fait dans un dépôt git, et j'utilise les commandes git clean -fdx ; git checkout . que je peux rappeler depuis mon historique des commandes via Ctrl-r la plupart du temps.
Et dans les autres cas, si les sources ne sont pas déjà dans git, alors les commandes git init . ; git add . ; git commit -m 'hopla' règlent le problème.
This milestone is not the end of the journey but rather the beginning of a new
one: the port will need to be rebootstrapped in the official archive, build
daemons will have to be reinstalled and handed over to
DSA, many bugs will need to be fixed. If everything
goes well, the architecture will eventually be released with
Trixie. Please note that this
process will be long and will span several months.
Over the years, the Debian GNU/kFreeBSD
port has gone through various
phases. After many years of development, it was released as technology
preview with the release of
Squeeze and eventually became an
official architecture with the release of
Wheezy. However it ceased being an
official architecture a couple of years later with the release of Jessie,
although a
jessie-kfreebsd
suite was available in the official archive. Some years later, it was moved to
the debian-ports
archive, where it
slowly regressed over the years. The development totally has now been stopped
for over a year,
and the port has been
removed from the
debian-ports archive. It's time to say it goodbye!
I feel a touch of nostalgia as I was deeply involved in the Debian GNU/kFreeBSD
port for nearly a decade, starting in 2006. There are many different reasons to
like GNU/kFreeBSD ranging from political to technical considerations.
Personally, I liked the technical aspect, as the FreeBSD kernel, at that time,
was ahead of the Linux kernel in term of features: jails, ZFS, IPv6 stateful
firewalling, and at a later point superpages. That said it was way behind for
hardware support and to the best of my knowledge this remains unchanged.
Meanwhile, the Linux kernel development accelerated in the latter stages of the
2.6.x series, and eventually closed the feature gap. At some point, I began to
lose interest, and also to lack time, and slowly stepped away from its
development.
J'ai écrit auparavant que quand Firefox reçoit un fichier dont le
type média est text/markdown, il le propose au téléchargement, alors que les
autres navigateurs l'affichent comme un fichier texte.
Il est maintenant possible de plusser sur
connect.mozilla.org
pour demander que Firefox formatte le markdown par défaut.
A few months ago, I switched my backup server to an ODROID-M1
SBC. It uses a RK3568 SoC with a
quad-core Cortex-A55 and AES extensions (useful for disk encryption), and I
added a 2 TB NVME SSD to the M2 slot. It also has a SATA connector, but the
default enclosure does not have space for 2.5" drives. It's not the fastest
SBC, but it runs stable and quite well as a backup server, and it's fanless,
and low-power (less than 2 W idle). The support for the SoC has been added
recently to the Linux kernel (it's used by various SBC), however the device
tree for the ODROID-M1 was missing, so I
contributed
it based on the vendor one, and also submitted a few small fixes.
All the changes ended in the Bookworm kernel, and with the Bookworm release
approaching, I decided it was the good moment to upgrade it. It went quite
well, and now I can enjoy running dist-upgrade like on other stable servers
without having to care about the kernel. I am currently using
Borg as a backup software, but the upgrade also
gave access to a newer Restic version supporting
compression (a must have for me), so I may give it a try.
For over 15 years, I've hardly made any updates to my website, and it remains
low on my priority list. So I made a radical decision to replace it entirely
with my blog. The content of the website has been reduced to just two
additionalpages.
But nothing has been lost: nowadays, Wikipedia is a much better platform for
sharing knowledge than random websites. And it happens that they already cover
all that was on my website about
subaquatic diving in French.
They also offer a multitude of resources in electronics, including the topics that
were on my website:
LCD displays,
I²C bus,
barcodes,
parallel ports,
serial ports, and
DCF77 reception.
Update: thanks to the very kind involvment of the widow of our wemaster, we
could provide enough private information to Dreamhost, who finally accepted to
reset the password and the MFA. We have recovered evrything! Many thanks to
everybody who helped us!
Due to tragic circumstances, one association that I am part of,
Sciencescope got locked out of its account at
Dreamhost. Locked out, we can not pay the annual bill. Dreamhost contacted us
about the payment, but will not let us recover the access to our account in
order to pay. So they will soon close the account. Our website, mailing lists
and archives, will be erased. We provided plenty of evidence that we are not
scammers and that we are the legitimate owners of the account, but reviewing it
is above the pay grade of the custommer support (I don't blame them) and I
could not convince them to let somebody higher have a look at our case.
If you work at Dreamhost and want to keep us as custommers instead of kicking
us like that, please ask the support service in charge of ticket 225948648 to
send the recovery URL to the secondary email adddresses (the ones you used to
contact us about the bill!) in addition to the primary one (which nobody will
read anymore). You can encrypt it for my Debian Developer key
73471499CC60ED9EEE805946C5BD6C8F2295D502 if you worry it gets in wrong hands.
If you still have doubts I am available for calls any time.
If you know somebody working at Dreamhost can you pass them the message?
This would be a big, big, relief for our non-profit association.
Akvorado collecte des flux sFlow et IPFIX, les stocke dans une base
de données ClickHouse et les présente dans une console web. Bien qu’il n’y
ait pas de détection de DDoS intégrée, il est possible d’en créer une à
partir de requêtes pour ClickHouse.
Supposons que nous voulions détecter des attaques DDoS ciblant nos clients. À
titre d’exemple, nous considérons une attaque DDoS comme une collection de flux
sur une minute ciblant une adresse IP client unique, à partir d’un
port source unique et correspondant à l’une de ces conditions :
une bande passante moyenne de 1 Gbit/s,
une bande passante moyenne de 200 Mbit/s lorsque le protocole est UDP,
plus de 20 adresses IP sources et une bande passante moyenne de 100 Mbit/s, ou
plus de 10 pays sources et une bande passante moyenne de 100 Mbit/s.
Voici la requête SQL pour détecter de telles attaques au cours des 5 dernières
minutes :
La méthode la plus simple consiste à sacrifier l’utilisateur attaqué. Bien que
cela aide l’attaquant, cela protège avant tout votre réseau. C’est une méthode
prise en charge par tous les routeurs. Vous pouvez également déléguer cette
protection à la plupart des fournisseurs de transit. Cela est utile si le volume
des attaques dépasse la capacité de votre connexion Internet.
Cela fonctionne en annonçant avec BGP une route vers l’utilisateur attaqué avec
une communauté spécifique. Le routeur de bordure modifie l’adresse du prochain
routeur de ces routes vers une adresse IP spécifique configurée pour transférer
le trafic vers l’interface « nulle ». La RFC 7999 définit 65535:666 à
cette fin. C’est ce qu’on appelle un trou noir déclenché à distance (“remote
triggered blackhole”, RTBH) et expliqué en détail dans la RFC 3882.
Il est également possible de bloquer la source des attaques en utilisant uRPF
défini dans la RFC 3704. C’est expliqué dans la RFC 5635. Cependant,
uRPF peut être une charge importante pour les ressources de votre routeur.
Consultez “NCS5500 uRPF: Configuration et Impact sur l’échelle” pour un exemple des types de restrictions
auxquelles vous devez vous attendre lorsque vous activez uRPF.
Pour annoncer les routes, nous pouvons utiliser BIRD. Voici un fichier de
configuration complet pour permettre à tout routeur de les collecter :
log stderr all;
router id 192.0.2.1;protocol device {
scan time 10;}protocol bgp exporter {
ipv4 {
import none;
export where proto = "blackhole4";};
ipv6 {
import none;
export where proto = "blackhole6";};
local as 64666; neighbor range 192.0.2.0/24 external;
multihop;
dynamic name "exporter";
dynamic name digits 2;
graceful restart yes;
graceful restart time 0; long lived graceful restart yes;
long lived stale time 3600;# keep routes for 1 hour!}protocol static blackhole4 {
ipv4;
route 203.0.113.206/32 blackhole { bgp_community.add((65535, 666));
}; route 203.0.113.68/32 blackhole { bgp_community.add((65535, 666));
};}protocol static blackhole6 {
ipv6;
}
Nous utilisons BGP LLGR pour garantir que les routes sont conservées pendant
une heure, même si la connexion BGP est interrompue, notamment pendant une
maintenance.
Du côté du récepteur, si vous disposez d’un routeur Cisco fonctionnant sous IOS
XR, vous pouvez utiliser la configuration suivante pour éliminer le trafic reçu
sur la session BGP. Comme la session BGP est dédiée à cette utilisation, la
communauté 65535:666 n’est pas utilisée, mais vous pouvez aussi transférer ces
routes à vos fournisseurs de transit.
router static
vrf public
address-family ipv4 unicast
192.0.2.1/32 Null0 description "BGP blackhole" !address-family ipv6 unicast
2001:db8::1/128 Null0 description "BGP blackhole" ! !!route-policy blackhole_ipv4_in_public
if destination in (0.0.0.0/0 le 31) then
dropendifset next-hop 192.0.2.1doneend-policy!route-policy blackhole_ipv6_in_public
if destination in (::/0 le 127) then
dropendifset next-hop 2001:db8::1doneend-policy!router bgp 12322neighbor-group BLACKHOLE_IPV4_PUBLIC
remote-as64666ebgp-multihop255update-source Loopback10
address-family ipv4 unicast
maximum-prefix10090route-policy blackhole_ipv4_in_public in
route-policy drop out
long-lived-graceful-restart stale-time send 86400 accept 86400 !address-family ipv6 unicast
maximum-prefix10090route-policy blackhole_ipv6_in_public in
route-policy drop out
long-lived-graceful-restart stale-time send 86400 accept 86400 ! !vrf public
neighbor192.0.2.1use neighbor-group BLACKHOLE_IPV4_PUBLIC
description akvorado-1
Lorsque le trafic est éliminé, il est toujours remonté par IPFIX et sFlow.
Dans Akvorado, utilisez ForwardingStatus >= 128 comme filtre pour
sélectionner celui-ci.
Bien que cette méthode soit compatible avec tous les routeurs, elle permet à
l’attaque de réussir car la cible est complètement inaccessible. Si votre
routeur le prend en charge, Flowspec peut filtrer sélectivement les flux pour
arrêter l’attaque sans affecter le client.
Flowspec est défini dans la RFC 8955 et permet la transmission de
spécifications de flux dans des sessions BGP. Une spécification de flux est un
ensemble de critères à appliquer au trafic IP. Ceux-ci incluent le préfixe
source et destination, le protocole IP, le port source et destination et la
longueur des paquets. Chaque spécification de flux est associée à une action,
encodée sous forme d’une communauté étendue : limitation du trafic, marquage ou
redirection.
Pour annoncer des spécifications de flux avec BIRD, nous complétons notre
configuration. La communauté étendue utilisée limite le trafic correspondant à 0
octet par seconde.
flow4 table flowtab4;
flow6 table flowtab6;
protocol bgp exporter {
flow4 {
import none;
export where proto = "flowspec4";};
flow6 {
import none;
export where proto = "flowspec6";};# […]}protocol static flowspec4 {
flow4;
route flow4 {
dst 203.0.113.68/32;
sport = 53;
length >= 1476 && <= 1500;
proto = 17;}{
bgp_ext_community.add((generic, 0x80060000, 0x00000000));
};
route flow4 {
dst 203.0.113.206/32;
sport = 123;
length = 468;
proto = 17;}{
bgp_ext_community.add((generic, 0x80060000, 0x00000000));
};}protocol static flowspec6 {
flow6;
}
Si vous avez un routeur ASR tournant sous IOS XR, la configuration ressemble à ceci :
vrf public
address-family ipv4 flowspec
address-family ipv6 flowspec
!router bgp 12322address-family vpnv4 flowspec
address-family vpnv6 flowspec
neighbor-group FLOWSPEC_IPV4_PUBLIC
remote-as64666ebgp-multihop255update-source Loopback10
address-family ipv4 flowspec
long-lived-graceful-restart stale-time send 86400 accept 86400route-policy accept in
route-policy drop out
maximum-prefix10090validation disable
!address-family ipv6 flowspec
long-lived-graceful-restart stale-time send 86400 accept 86400route-policy accept in
route-policy drop out
maximum-prefix10090validation disable
! !vrf public
address-family ipv4 flowspec
address-family ipv6 flowspec
neighbor192.0.2.1use neighbor-group FLOWSPEC_IPV4_PUBLIC
description akvorado-1
Ensuite, il convient d’activer Flowspec sur toutes les interfaces :
C’est une addition importante : les requêtes DNS légitimes ont une taille
inférieure à cela et ne sont donc pas filtrées2. Avec ClickHouse, vous pouvez
obtenir les 10ème et 90ème centiles des tailles de paquets
avec quantiles(0.1, 0.9)(Bytes/Packets).
Le dernier problème que nous devons résoudre est de rendre les requêtes plus
rapides : elles peuvent avoir besoin de plusieurs secondes pour collecter les
données et sont susceptibles de consommer des ressources substantielles de votre
base de données ClickHouse. Une solution consiste à créer une vue matérialisée
pour pré-agréger les résultats :
La table ddos_logs utilise le moteur SummingMergeTree. Lorsque la table
reçoit de nouvelles données, ClickHouse remplace toutes les lignes ayant la
même clé de tri, telle que définie par la directive ORDER BY, par une seule
ligne qui contient des valeurs résumées3 en utilisant soit la
fonction sum() soit la fonction d’agrégation explicitement spécifiée
(uniqCombined et quantiles dans notre exemple).
Enfin, nous modifions notre requête initiale avec la requête suivante :
Pour résumer, la construction d’un système de suppression des attaques DDoS
nécessite de suivre les étapes suivantes :
définir un ensemble de critères pour détecter une attaque DDoS
traduire ces critères en requêtes SQL
pré-agréger les flux dans des tables SummingMergeTree
interroger et transformer les résultats en un fichier de configuration pour BIRD
configurer vos routeurs pour extraire les routes de BIRD
Un script Python comme celui qui suit permet de gérer la quatrième étape. Pour
chaque cible attaquée, il génère à la fois une règle Flowspec et une route de
type « trou noir ».
Jusqu’à ce qu’Akvorado intègre la détection et la lutte contre les attaques
DDoS, les idées présentées dans ce billet fournissent une base solide pour
commencer à construire votre propre système anti-DDoS. 🛡️
ClickHouse peut exporter les résultats au format Markdown en
ajoutant FORMAT Markdown à la requête. ↩︎
Bien que la plupart des clients DNS réessaient avec TCP en cas d’échec,
ce n’est pas toujours le cas : jusqu’à récemment, la
bibliothèque Musl ne le faisait pas. ↩︎
La vue matérialisée agrège également les données qu’elle a sous
la main, à la fois pour l’efficacité et pour s’assurer que nous travaillons
avec les bons types de données. ↩︎
Akvorado collecte les flux réseau à l’aide d’IPFIX ou de sFlow. Il
les stocke dans une base de données ClickHouse. Une console web permet à
l’utilisateur de faire des requêtes sur les données pour obtenir des graphiques.
Un aspect intéressant de cette console est la possibilité de filtrer les flux
avec un langage inspiré de SQL :
Filter editor in Akvorado console
Souvent, les interfaces web exposent un constructeurde
requêtes pour concevoir de tels filtres. À la place, j’ai
choisi de combiner un langage similaire à SQL avec un éditeur prenant en charge
la complétion, la coloration syntaxique et la vérification
syntaxique1.
pigeon génère un analyseur pour Go. Une grammaire est un ensemble de règles.
Chaque règle est un identifiant, avec optionnellement une étiquette utilisée pour les messages
d’erreur, une expression et une action en Go à exécuter. Vous pouvez trouver la
grammaire complète dans parser.peg. Voici une règle simplifiée :
L’identifiant de la règle est ConditionIPExpr. Elle attend soit
ExporterAddress, soit SrcAddr, soit DstAddr, sans distinction de la case.
L’action pour chaque cas renvoie le nom de la colonne correspondante. C’est ce
qui est stocké dans la variable column. Ensuite, elle attend un des deux
opérateurs possibles. Comme il n’y a pas de bloc de code, l’opérateur est stocké
dans la variable operator. Ensuite, elle attend une chaîne validée par la
règle IP qui est définie ailleurs dans la grammaire. Si c’est le cas, elle
stocke le résultat dans la variable ip et exécute l’action finale. L’action
transforme la colonne, l’opérateur et l’adresse IP en une expression SQL pour
ClickHouse. Par exemple, si nous avons ExporterAddress = 203.0.113.15, nous
obtenons ExporterAddress = IPv6StringToNum('203.0.113.15').
La règle IP utilise une expression régulière rudimentaire mais vérifie si
l’adresse correspondante est correcte dans le bloc d’action, grâce à
netip.ParseAddr():
IP "IP address"←[0-9A-Fa-f:.]+ {ip,err:=netip.ParseAddr(string(c.text))iferr!=nil{return"",errors.New("expecting an IP address")}returnip.String(),nil}
Cet analyseur transforme de manière sécurisée un filtre en une clause WHERE
acceptée par ClickHouse3 :
CodeMirror est un éditeur de code polyvalent qui peut être facilement
intégré dans les projets JavaScript. Dans Akvorado, le composant
Vue.jsInputFilter utilise CodeMirror et tire
parti de fonctionnalités telles que la coloration syntaxique, la vérification
syntaxique et la complétion. Le code source de ces fonctionnalités se trouve
dans le répertoire codemirror/lang-filter/.
La grammaire PEG pour Go ne peut pas être utilisé directement4 et les
exigences pour les analyseurs syntaxiques utilisés dans les éditeurs sont
différentes : ils doivent être tolérants aux erreurs et fonctionner de manière
incrémentielle, car le code est généralement mis à jour caractère par caractère.
CodeMirror propose une solution via son propre générateur d’analyseur, Lezer.
Nous n’avons pas besoin que cet analyseur supplémentaire comprenne pleinement le
langage des filtres. Seule la structure est nécessaire : les noms de colonnes, les
opérateurs de comparaison et de logique, les valeurs entre guillemets ou non. La
grammaire est donc assez courte et n’a pas besoin d’être mise à jour
souvent :
La vérification syntaxique est déléguée à l’analyseur syntaxique en Go. Le point
d’accès /api/v0/console/filter/validate accepte un filtre et retourne une
structure JSON avec les éventuelles erreurs:
{"message":"at line 1, position 12: string literal not terminated","errors":[{"line":1,"column":12,"offset":11,"message":"string literal not terminated",}]}
Le greffon pour CodeMirror interroge cette API et transforme
chaque erreur en un diagnostic.
Le système de complétion adopte une approche hybride. Il répartit le travail
entre le frontend et le backend pour offrir ses suggestions.
Le frontend utilise l’analyseur construit avec Lezer pour déterminer le
contexte de la complétion : s’agit-il compléter un nom de colonne, un opérateur
ou une valeur ? Il extrait également le nom de la colonne si nous complétons
autre chose. Il transfère le résultat au backend via le point de terminaison
/api/v0/console/filter/complete. Parcourir l’arbre syntaxique n’a pas été
aussi facile que je le pensais, mais les tests unitaires ont
beaucoup aidé.
Le backend utilise l’analyseur généré par pigeon pour compléter les noms
de colonnes et les opérateurs de comparaison. Pour les valeurs, les complétions
sont statiques out extraites de la base de données ClickHouse. Un utilisateur
peut compléter un numéro AS à partir d’un nom d’organisation grâce au code
suivant :
results:=[]struct{Labelstring`ch:"label"`Detailstring`ch:"detail"`}{}columnName:="DstAS"sqlQuery:=fmt.Sprintf(` SELECT concat('AS', toString(%s)) AS label, dictGet('asns', 'name', %s) AS detail FROM flows WHERE TimeReceived > date_sub(minute, 1, now()) AND detail != '' AND positionCaseInsensitive(detail, $1) >= 1 GROUP BY label, detail ORDER BY COUNT(*) DESC LIMIT 20`,columnName,columnName)iferr:=conn.Select(ctx,&results,sqlQuery,input.Prefix);err!=nil{c.r.Err(err).Msg("unable to query database")break}for_,result:=rangeresults{completions=append(completions,filterCompletion{Label:result.Label,Detail:result.Detail,Quoted:false,})}
À mon avis, ce système de complétion est un élément important qui fait de
l’éditeur un moyen efficace de sélectionner des flux. Alors qu’un constructeur
de requêtes aurait pu être plus convivial pour les débutants, la facilité
d’utilisation et les fonctionnalités du système de complétion le rendent plus
agréable à utiliser une fois que l’utilisateur familiarisé.
De plus, créer un constructeur de requêtes me semblait une tâche assez
rébarbative. ↩︎
Mes WC sont équipés d’une chasse d’eau avec plaque de déclenchement Geberit
Sigma 70. Le discours commercial autour de ce dispositif à asservissement
hydraulique vante le « mécanisme révolutionnaire qui n’utilise pas
d’électronique embarquée ». En pratique, le déclenchement est très capricieux et
a un taux d’échec particulièrement élevé. Évitez ce type de mécanisme !
Préférez lui une version intégralement mécanique comme le Geberit Sigma 20.
Après le passage de plusieurs plombiers, des échanges avec le service technique
de Geberit et le remplacement à grands frais de l’intégralité du mécanisme,
j’observais toujours un taux d’échec de plus de 50% pour la petite chasse. J’ai
finalement réussi à réduire ce taux à 5% en appliquant deux patins ronds en
silicone transparent de 8 mm de diamètre sur le dos de la plaque de
déclenchement. Leurs emplacements sont indiqués par des ronds rouges sur la
photo ci-dessous :
Mécanisme Geberit Sigma 70. En haut: le mécanisme posé en applique. En bas, le dos de la plaque de déclenchement en verre. En rouge, les deux emplacements où appliquer les patins.
Comptez environ 5 € et autant de minutes pour cette opération.
Les Protocol Buffers sont un choix populaire pour la sérialisation de données
structurées en raison de leur taille compacte, de leur rapidité de traitement,
de leur indépendance du langage cible et de leur compatibilité. D’autres
alternatives existent, notamment Cap’n Proto, CBOR et Avro.
Les structures de données sont habituellement décrites dans un fichier de
définition de protocole (.proto). Le compilateur protoc et un greffon
spécifique à un langage les convertissent en code:
Akvorado collecte les flux réseau à l’aide de IPFIX ou sFlow, les
décode à l’aide de GoFlow2, les encode en Protocol Buffers et les envoie à
Kafka pour les stocker dans une base de données ClickHouse. La collecte
d’un nouveau champ, comme les adresses MAC source et destination, nécessite des
modifications à plusieurs endroits, y compris le fichier de définition de
protocole et le code de migration pour ClickHouse. De plus, le coût est supporté
par tous les utilisateurs1. Il serait agréable d’avoir un schéma commun
à l’application et de permettre aux utilisateurs d’activer ou de désactiver
les champs dont ils ont besoin.
Bien que le principal objectif est la flexibilité, nous ne voulons pas sacrifier
les performances. Sur ce front, c’est un véritable succès: lors de la mise à
niveau de 1.6.4 à 1.7.1, les performances de décodage et d’encodage ont presque
doublé ! 🤗
J’utilise le code suivant pour mesurer les performances du
processus de décodage et d’encodage. Initialement, la méthode Decode() est une
simple façade au-dessus du producteur GoFlow2. Elle stocke les données
décodées dans la structure en mémoire générée par protoc. Par la suite,
certaines données seront encodées directement pendant le décodage des flux.
C’est pourquoi nous mesurons à la fois le décodage et l’encodage2.
L’implémentation Go de référence pour les Protocol Buffers,
google.golang.org/protobuf n’est pas la plus
efficace. Pendant longtemps, l’alternative la plus courante était
gogoprotobuf. Cependant, le projet est maintenant obsolète.
vtprotobuf est un bon remplacement3.
Nous avons désormais une bonne référence départ. Voyons comment encoder nos
Protocol Buffers sans un fichier .proto. Le format utilisé est relativement
simple et repose beaucoup sur les entiers à longueur variable.
Les entiers à longueur variable sont un moyen efficace d’encoder des entiers non
signés en utilisant un nombre variable d’octets, de un à dix, les petites
valeurs utilisant moins d’octets. Ils fonctionnent en scindant les entiers par
groupe de 7 bits et en utilisant le 8ème bit comme signal de
continuation : il est mis à 1 pour tous les groupes sauf le dernier.
Encodage des entiers à longueur variable
Pour notre utilisation, nous avons besoin de deux types seulement : les entiers
à longueur variable et les séquences d’octets. Une séquence d’octets est codée en
la préfixant par sa longueur sous forme d’entier à longueur variable. Lorsqu’un
message est codé, chaque couple clé-valeur est transformé en un enregistrement
composé d’un numéro de champ, d’un type et de la valeur. Le numéro de champ et
le type sont codés en un seul entier de longueur variable appelé « tag ».
Message codé avec les Protocol Buffers
Nous utilisons les fonctions bas niveau suivantes pour construire le message
codé :
Notre abstraction pour le schéma contient les informations appropriées pour
coder un message (ProtobufIndex) et pour générer un fichier de définition de
protocole (les champs commençant par Protobuf) :
typeColumnstruct{KeyColumnKeyNamestringDisabledbool// […]// For protobuf.ProtobufIndexprotowire.NumberProtobufTypeprotoreflect.Kind// Uint64Kind, Uint32Kind, …ProtobufEnummap[int]stringProtobufEnumNamestringProtobufRepeatedbool}
Nous avons quelques méthodes simples autour des fonctions
protowire pour encoder directement les champs lors du décodage des flux. Ils
sautent les champs désactivés ou ceux déjà encodés mais non répétables. Voici un
extrait du décodeur sFlow:
Les champs nécessaires dans la suite du traitement, comme les adresses source et
destination, sont stockés non codés dans une structure séparée :
typeFlowMessagestruct{TimeReceiveduint64SamplingRateuint32// For exporter classifierExporterAddressnetip.Addr// For interface classifierInIfuint32OutIfuint32// For geolocation or BMPSrcAddrnetip.AddrDstAddrnetip.AddrNextHopnetip.Addr// Core component may override themSrcASuint32DstASuint32GotASPathbool// protobuf is the protobuf representation for the information not contained above.protobuf[]byteprotobufSetbitset.BitSet}
Le tableau protobuf contient les données encodées. Il est initialisé avec une
capacité de 500 octets pour éviter les redimensionnements pendant l’encodage. Il
y a également quelques octets réservés au début pour pouvoir encoder la taille
totale en tant qu’entier de longueur variable. Lors de la finalisation de
l’encodage, les champs restants sont ajoutés et la longueur du message est
insérée dans l’espace libre au début :
func(schema*Schema)ProtobufMarshal(bf*FlowMessage)[]byte{schema.ProtobufAppendVarint(bf,ColumnTimeReceived,bf.TimeReceived)schema.ProtobufAppendVarint(bf,ColumnSamplingRate,uint64(bf.SamplingRate))schema.ProtobufAppendIP(bf,ColumnExporterAddress,bf.ExporterAddress)schema.ProtobufAppendVarint(bf,ColumnSrcAS,uint64(bf.SrcAS))schema.ProtobufAppendVarint(bf,ColumnDstAS,uint64(bf.DstAS))schema.ProtobufAppendIP(bf,ColumnSrcAddr,bf.SrcAddr)schema.ProtobufAppendIP(bf,ColumnDstAddr,bf.DstAddr)// Add length and move it as a prefixend:=len(bf.protobuf)payloadLen:=end-maxSizeVarintbf.protobuf=protowire.AppendVarint(bf.protobuf,uint64(payloadLen))sizeLen:=len(bf.protobuf)-endresult:=bf.protobuf[maxSizeVarint-sizeLen:end]copy(result,bf.protobuf[end:end+sizeLen])returnresult}
Minimiser les allocations est essentiel pour maintenir de bonnes performances.
Les tests doivent être exécutés avec le drapeau -benchmem pour surveiller le
nombre d’allocations : chacune entraîne un coût indirect pour le ramasse-miette.
Le profileur Go est un outil précieux pour identifier les zones
du code qui peuvent être optimisées :
$ gotest-run=__nothing__-bench=Netflow/with_encoding\> -benchmem-cpuprofileprofile.out\> akvorado/inlet/flow
goos: linuxgoarch: amd64pkg: akvorado/inlet/flowcpu: AMD Ryzen 5 5600X 6-Core ProcessorNetflow/with_encoding-12 143953 7955 ns/op 8256 B/op 134 allocs/opPASSok akvorado/inlet/flow 1.418s$ gotoolpprofprofile.out
File: flow.testType: cpuTime: Feb 4, 2023 at 8:12pm (CET)Duration: 1.41s, Total samples = 2.08s (147.96%)Entering interactive mode (type "help" for commands, "o" for options)(pprof)web
Après avoir utilisé le schéma interne au lieu du code généré à
partir du fichier de définition, les performances se sont améliorées. Cependant,
cette comparaison n’est pas tout à fait équitable car moins d’informations sont
décodées et, auparavant, GoFlow2 décodait les flux vers sa propre structure
qui était ensuite copiée dans notre version.
Concernant les tests, nous utilisons
github.com/jhump/protoreflect : le paquet protoparse analyse
le fichier de définition que nous avons construit dynamiquement et le paquet
dynamic décode les messages. Jetez un œil à la méthode ProtobufDecode()
method pour plus de détails4.
Pour obtenir les chiffres finaux, j’ai aussi optimisé le décodage dans
GoFlow2. Il s’appuyait fortement sur binary.Read(). Cette
fonction peut utiliser la réflexion dans certains cas et chaque appel alloue un
tableau d’octets pour lire les données. En la remplaçant par une version plus
efficace, on obtient encore une amélioration notable des performances :
Il est maintenant plus facile de collecter de nouvelles données et
le composant recevant les flux est désormais plus rapide ! 🚅
Note
La plupart des paragraphes ont été traduits de l’anglais par
ChatGPT en utilisant les instructions suivantes : “From now
on, I will paste Markdown code in English and I would like you to translate it
to French. Keep the markdown markup and enclose the result into a code block.
Thanks.” Le résultat a été légèrement édité si nécessaire. Comparé à
DeepL, ChatGPT est capable de conserver le formatage, les anglicismes,
mais son français est moins bon et il est nécessaire de lui rappeler
régulièrement les instructions.
Bien que les champs vides ne sont pas sérialisés en Protocol Buffers,
les colonnes vides dans ClickHouse occupent de la place, même si
elles se compressent bien. De plus, les champs inutilisés sont toujours
décodés et peuvent encombrer l’interface. ↩︎
Il existe une fonction similaire pour NetFlow. Les protocoles
NetFlow et IPFIX sont moins complexes à décoder que sFlow car ils utilisent
une structure TLV plus simple. ↩︎
vtprotobuf génère un code mieux optimisé en supprimant un
niveau d’indirection. Il produit du code codant chaque champ en octets :
Quand Firefox reçoit un fichier dont le type média est text/markdown, il le
propose au téléchargement, alors que les autres navigateurs l'affichent comme
un fichier texte. Dans le ticket 1319262, il est proposé d'afficher les
fichiers Markdown par défaut. Mais il faudrait un patch…
Une conversation sur la list debian-project a attiré mon attention sur un mot
italien signifiant quelque chose comme « auriez-vous la gentillesse d'aller
voir ailleurs ? », mais en version plus directe et vulgaire. J'ai ensuite
utilisé http://codesearch.debian.net pour étudier plus en détail son emploi.
Je l'ai trouvé dans :
le code source de XEmacs ;
une liste de gros mots pour policer les conversations dans BZFlag ;
le générateur aléatoire de phrases PolyGen ;
le code source du jeu de plateau Tagua ;
une base de données d'épigrammes vulguaires pour la plateforme éducative WIMS ;
le jeu de mots croisés parololottero ;
une base de données d'épigrammes vulguaires pour messages de bienvenue ou signatures de courriels ;
des listes de mots de passes trop fréquents ;
un commentaire destiné à un déonmmé Wolf dans le code source d'un autre programme ;
a collection of rude gestures in the xwrists package.
Ce fut une promenade rafraîchissante et récréactive dans l'univers des paquets
Debian.
Dans les mois qui viennent, trois évènements auront lieu dans lesquels l'association Debian France tiendra un stand afin d'y faire de la promotion du projet Debian, mais aussi pour y proposer quelques goodie.
Comme chaque évènement, nous sommes à la recherche de volontaires pour tenir le stand Debian France. Pour chacun d'eux, un Framadate est ouvert pour recenser les volontaires et leurs disponibilités.
Il s'agit d'un salon ou le stand Debian est tenu par de membres Debian France mais aussi des contributeurs d'autres pays. La page d'inscription n'est pas encore ouverte, mais sera disponible sur le Wiki Debian à l'adresse suivante : https://wiki.debian.org/DebianEvents/be
N'hésitez pas à contacter l'association pour toutes question à l'adresse asso@france.debian.net ou bien sur IRC, réseau OFTC, canal #debian-france.
Bien à vous et en espérant vous compter parmi nous,
screenshots.debian.net est un service qui permet d’afficher des captures d’écran de logiciels. C’est assez pratique pour se faire une idée d’une interface par exemple. Une capture d’écran montrait déjà l’interpréteur Brainfuck beef affichant un classique Hello Word!. Mais on peut aussi personnaliser en affichant un Hello Debian! :
Brainfuck
Brainfuck est un langage dont l’intérêt principal est d’être difficilement compréhensible par un humain. Pas la peine de s’étendre sur ses spécificités, wikipedia le fait très bien. Il ressemble à une machine de Turing: le programme déplace un curseur dans un tableau et modifie les valeurs contenues dans les cellules du tableau.
Voici une version commentée du programme utilisé (le début est quasi-identique au hello world fourni sur la page wikipedia puisqu’on veut écrire la même chose) :
++++++++++ affecte 10 à la case 0
[ boucle initialisant des valeurs au tableau
> avance à la case 1
+++++++ affecte 7 à la case 1
> avance à la case 2
++++++++++ affecte 10 à la case 2
> avance à la case 3
+++ affecte 3 à la case 3
> avance à la case 4
+ affecte 1 à la case 4
> avance à la case 5
+++++++++++ affecte 11 à la case 5
<<<<< retourne à la case 0
- enlève 1 à la case 0
] jusqu'à ce que la case 0 soit = à 0
La boucle initialise le tableau en 10 itérations et son état est alors :
Case
0
1
2
3
4
5
Valeur
0
70
100
30
10
110
Suite du programme :
>++ ajoute 2 à la case 1 (70 plus 2 = 72)
. imprime le caractère 'H' (72)
>+ ajoute 1 à la case 2 (100 plus 1 = 101)
. imprime le caractère 'e' (101)
+++++++ ajoute 7 à la case 2 (101 plus 7 = 108)
. imprime le caractère 'l' (108)
. imprime le caractère 'l' (108)
+++ ajoute 3 à la case 2 (108 plus 3 = 111)
. imprime le caractère 'o' (111)
>++ ajoute 2 à la case 3 (30 plus 2 = 32)
. imprime le caractère ' '(espace) (32)
<<< revient à la case 0
++ ajoute 2 à la case 0 (0 plus 2 = 2)
[ une boucle
> avance à la case 1
-- enlève 4 à la case 1 (72 moins 4 = 68)
> avance à la case 2
----- enlève 10 à la case 2 (111 moins 10 = 101)
<< retourne à la case 0
- enlève 1 à la case 0
] jusqu'à ce que la case 0 soit = à 0
> va case 1
. affiche 'D'
> va case 2
. affiche 'e'
--- enlève 3 à la case 2 (101 moins 3 = 98)
. affiche 'b'
>>> va case 5
----- enlève 5 à la case 5
. affiche 'i'
<<< va case 2
- enlève 1 à la case 2
. affiche 'a'
>>> va case 5
+++++ ajoute 5 à la case 5
. affiche 'n'
<< va à la case 3
+ ajoute 1 à la case 3
. affiche un point d'exclamation
> va à la case 4
. imprime le caractère 'nouvelle ligne' (10)
screenshots.debian.net
Une capture de l’exécution du programme est disponible pour les interpréteurs beef et hsbrainfuck sur screenshot.debian.net.
Les images disponibles sur screenshots.debian.net sont aussi réutilisées par le service packages.debian.org (par exemple packages.debian.org) et par certains gestionnaires de paquets.
Si vous avez envie d’ajouter des captures d’écran à des paquets qui n’en auraient pas (les plus courants sont déjà faits), sachez que l’affichage n’est pas direct car il y a une validation manuelle des images envoyées. Le délai reste limité à quelques jours (voire à la journée).
Rappelons que Richard Stallman n’est rien de moins que l’inventeur des quatre libertés essentielles définissant le logiciel libre et du concept juridique de copyleft, ainsi que le fondateur de la Free Software Foundation et du projet GNU (Linux sans le noyau).
Steve Langasek a ensuite soumis une General Resolution (GR) proposant que la personne morale Debian soutienne officiellement la prise de position de ses leaders. Mais rien ne s’est passé comme prévu, et ce qui devait être un référendum consensuel a tourné au pugilat sur la mailing list debian-vote en mars et en avril, ces discussions publiques n’étant bien sûr que la partie émergée de l’iceberg.
Huit options ont finalement été soumises au vote :
« Denounce the witch-hunt against RMS and the FSF »
« Debian will not issue a public statement on this issue »
« Further Discussion » (default option)
Pour faire court, c’est l’option 7 qui l’a emporté : Debian will not issue a public statement on this issue. Voici une représentation du résultat du scrutin qui utilise la méthode Condorcet :
En s’essayant à un peu de taxinomie politique, on constate que les options peuvent être classées en trois groupes. Les options explicites, anti et pro parlent d’elles-mêmes, mais comment connaître l’orientation d’une option implicite ? Sans la condamner, mais en refusant de participer à une chasse aux sorcières, l’option 7 constitue bien un soutien implicite à RMS. Le nombre de voix par rapport à l’option par défaut Further Discussion est le moyen le plus simple d’évaluer ce vote :
anti-RMS explicite (droite) : options 1, 2, 3 et 4 pour 203 + 222 + 219 + 221 = 216 voix de moyenne
pro-RMS implicite (centre) : option 7 pour 277 voix
pro-RMS explicite (gauche) : options 5 et 6 pour 52 + 84 = 68 voix de moyenne
Concernant les suffrages exprimés, il n’y a donc pas eu de vol de scrutin et la méthode Condorcet évite effectivement les problèmes de type Ballon d’or 2018, où l’éparpillement des voix d’un camp permet à une option minoritaire de l’emporter. En effet, une large majorité des votants voulait la peau de RMS, mais cette large majorité voulait aussi préserver le projet Debian d’une explosion probable, et a permis à l’option centriste de l’emporter de justesse.
Cependant, le système de vote de Debian a failli sur un point fondamental mais qui n’avait pourtant jamais semblé poser problème jusqu’ici. En effet, un vote concernant une General Resolutionn’est pas secret, ce qui est une pratique totalitaire qui doit être changée. On peut ainsi consulter le détail des votes de chaque votant. S’agissant d’un sujet aussi controversé, la sincérité du scrutin a très probablement été altérée par un taux de participation inférieur à ce qu’il aurait pu être, avec seulement 420 votants sur 1018 Debian Developers.
La victoire de Jonathan est sans surprise, car sans réelle opposition, Sruthi Chandran incarnant pour la seconde année consécutive une candidature de témoignage – non-homme, non-blanc -, mais n’étant malheureusement pas une prétendante crédible à la victoire. Voici une représentation du résultat du scrutin qui utilise la méthode Condorcet :
Bravo à toi Jonathan, et bonne chance dans la mise en œuvre de ton programme !
Lorsqu’on corrige une anomalie ou qu’on a ajoute une fonctionnalité à un logiciel ou une bibliothèque, on peut la garder pour soi ou la partager. La deuxième solution demande un peu plus d’efforts à court terme mais est préférable à long terme.
Le délai de retour d’un correctif ou d’une amélioration dépend de l’endroit où il est proposé : plus il est poussé loin et plus il va mettre de temps à revenir mais le nombre de personnes/machines bénéficiant du correctif sera plus grand.
Les différentes possibilités
Gardé pour soi
Cette méthode est absente du schéma puisqu’elle consiste à ne pas envoyer la modification à l’extérieur. C’est le plus rapide à mettre en œuvre, d’autant plus que la qualité du correctif n’est validée qu’en interne (juste soi-même ou par l’équipe intégrant la modification). Diverses façons d’arriver à ses fins sont possibles comme surcharger la signature de la méthode qui pose problème, attraper l’erreur non traitée correctement, intégrer la bibliothèque dans le code et la modifier directement (vendoring), etc.
Par contre, personne d’autre ne bénéficie du correctif et personne d’extérieur ne fera une revue de code.
Publication solitaire
La vitesse de mise au point est équivalente à la méthode précédente. Le déploiement prend un peu de temps. Elle permet de rendre la modification disponible pour les autres utilisateurs s’ils la trouvent. Ce phénomène est visible avec l’incitation au fork proposée par les forges comme Github, Gitlab, Bitbucket, etc, sans pousser la modification vers le développeur amont (via une pull request). Cette technique est utilisée lorsque des développeurs :
forkent un dépôt,
créent un commit modifiant le nouveau dépôt,
font dépendre leur application de ce commit (npm install git+https://alice@forge...).
Cependant, ce comportement n’est pas limité aux forges publiques : il existait déjà avant en publiant le correctif dans un article de blog, une liste de diffusion (liste non exhaustive).
Envoyé vers la distribution
La correction est envoyée dans la distribution Linux utilisée ; c’est souvent fait en incluant la modification dans un fichier, attaché à un rapport de bogue sur la distribution.
Une fois que la modification sera intégrée et qu’un nouveau paquet sera publié, l’ensemble des utilisateurs, y compris l’auteur, en bénéficieront. Cela évite de maintenir la modification de son côté lorsque de nouvelles versions du paquet seront publiées. La durée d’intégration est plus longue selon la réactivité du mainteneur du paquet et le mode de publication (version espacée ou rolling release). Bien évidemment, le bénéfice de la modification sera perdu en cas de changement de distribution.
Cette solution est nécessaire pour corriger/améliorer un élément spécifique d’un paquet de la distribution. Cela peut arriver dans deux cas :
soit parce que c’est un paquet spécifique à la distribution (le paquet apt pour debian par exemple)
soit parce qu’une modification du logiciel spécifique à la distribution a une influence sur la modification soumise
Envoyé vers le développeur amont
Plutôt que d’envoyer le correctif vers la distribution utilisée, il est alors envoyé directement vers le développeur du logiciel. Si le développement est hébergé sur une forge publique, cela suppose le faire un fork (comme dans le cas d’une publication solitaire), puis de faire une pull request (terme Github), merge request (terme Gitlab). Sinon, il faut regarder quelle est la forme attendue : en postant sur une liste de diffusion, ou directement vers le mainteneur, etc. Il sera nécessaire de répondre aux remarques et demandes de corrections pour que la modification soit intégrée dans le logiciel amont.
Comme dans le cas d’une intégration dans la distribution, une fois intégrée, la modification sera disponible pour tous :
soit en réutilisant le logiciel directement via le paquet issus du langage (par exemple gem pour ruby, wheel pour python, crate pour Rust, etc.)
soit parce que la version du logiciel sera elle aussi intégrée dans la distribution et donc obtenue dans un paquet de la distribution
Ce type de contributions sont les plus longues à revenir au contributeur mais elles permettent le déploiement le plus large (et donc la plus grande disponibilité pour soi et pour les autres).
Autres considérations
S’il n’est pas possible d’attendre le retour de la modification, la solution optimale est de faire un correctif local et un envoi vers la distribution ou vers le développeur amont (pour qu’une solution long terme soit aussi disponible automatiquement).
Pour bénéficier de l’envoi amont, il faut que le temps de retour soit inférieur au temps de changement de techno/bibliothèque. Dans un écosystème où les outils et bibliothèques sont abandonnés très rapidement, l’effort d’intégration peut être perçu comme vain puisque la personne ayant fait le développement aura peu le temps d’en profiter. D’un point de vue général, avec une majorité de personnes faisant ce calcul, cela ne fait qu’empirer le problème, avec des multitudes de fork s’ignorant mutuellement, chacun avec une fonctionnalité ou une correction différente. Javascript me semble être dans cette situation.
À propos du schéma
Le schéma a été réalisé avec Dia, installable par le paquet du même nom pour Debian et dérivées. Fichier source .dia
J’ai participé au colloque IMT4ET de l’IMT, pour faire une courte présentation sur le thème des Travaux Pratiques à distance et des expérimentations sur les TP “virtuels” sur le Cloud sur lesquelles je travaille en ce moment.
J’y parle de Guacamole et MeshCentral, d’Antidote, de Eclipse Che et de Labtainers, les différents trucs excitants du moment, mais aussi de kubernetes, docker et de trucs louches comme du DevOps académique
Arrivé l’an passé derrière Sam Hartman presque à égalité avec Martin Michlmayr et Joerg Jaspert, Jonathan l’emporte logiquement cette année dans une élection sans réelle concurrence.
En effet, Brian Gupta avait immédiatement indiqué que le seul objet de sa candidature était de constituer un référendum, qui s’est révélé peu concluant, sur la création des fondations Debian US et Debian Europe ; tandis que la jeune indienne Sruthi Chandran, dont on devrait réentendre parler dans les prochaines années, manquait de légitimité pour le poste n’étant développeuse Debian que depuis un an.
Bravo à toi Jonathan, et bonne chance dans la mise en œuvre de ton programme !
L'assemblée générale annuelle de l'association Debian-France vient de se terminer. Pas de confinement ici, puisque tout se passe en ligne et peut donc continuer envers et contre tout. Pour rappel, Debian France est une association qui se propose de représenter Debian en France, voire en Europe puisqu'elle est la seule organisation de confiance (Trusted Organization) active du projet Debian sur ce continent. Ce statut lui permet ainsi de recueillir des dons pour le projet Debian et de gérer le budget du projet qui lui incombe, en parallèle du sien.
L'assemblée générale a renouvelé le tiers de son conseil d'administration, actant ainsi l'entrée de Cyril Brulebois, un développeur Debian de longue date, au sein de son organe directeur. Le CA a reconduit le bureau de 2019, mais a élu un nouveau président: Jean-Philippe MENGUAL.
2019 avait marqué un véritable redécolage de Debian France: présence marquée aux FOSDEM, au Capitole du libre, à Paris, Lyon, organisation d'une minidebconf à Marseille, d'un meet-up à Bordeaux. Elle espère faire pareil en 2020, mais avec une claire volonté de mieux associer la communauté francophone des développeurs et des utilisateurs de Debian. Tout ce que fait l'asso doit avoir un "label" Debian clair, être partagé ici, et avec le projet dans son ensemble quand un budget est nécessaire ou pour les événements d'ampleur internationale (minidebconf). Dès février, Debian France a, via Debian, soutenu la tenue d'un sprint de l'équipe Ruby par exemple.
L'association espère donc mieux communiquer avec toute la communauté et s'articuler avec toutes ses composantes, comme debian-facile.
L'enjeu, outre une promotion plus marquée de Debian (Ubuntu étant moins présent), c'est aussi d'inspirer des gens qui, en entendant parler des actions, peuvent vouloir y contribuer. Ils sont les bienvenus! Tenir les stands, participer aux choix de goodies, adhérer à l'association, candidater au conseil d'administration pour 2021, autant de choses qui aideront à faire vivre l'asso et promouvoir le projet Debian. L'asso est "trusted organization", donc gère une partie du budget de Debian, elle doit donc être composée, au CA et au bureau, de développeurs Debian (pas exclusivement mais bon). Autant dire qu'avec moins de 100 développeurs vivant en France, toute bonne volonté est bienvenue! Et toute candidature à être développeur Debian est une bonne idée si vous vous en sentez capable et en avez envie.
Haut-les-coeurs donc, et merci à tous ceux qui suivent l'association et le projet! L'association remercie tous ses membres qui ont participé à l'assemblée générale et son bureau qui a géré cette année avec enthousiasme et dynamisme. Elle espère que cette année sera riche en synergies et partages, dans l'esprit du logiciel libre.
Debian France tiendra un stand à l'occasion du Paris Open Source Summit, les 10 et 11 Décembre 2019 aux Docks de Paris - 87 Avenue des Magasins Généraux, 93300 Aubervilliers.
Des développeurs Debian ainsi que des membres de l'association Debian France seront là pour répondre à vos questions.
Des goodies Debian seront également disponibles !
Nous serons présents au village associatif, emplacement A32 parmi les nombreux autres stands.
Debian France tiendra un stand à l'occasion du Capitole du libre, les 16 et 17 novembre 2019 à l'INP-ENSEEIHT de Toulouse.
Des développeurs Debian ainsi que des membres de l'association Debian France seront là pour répondre à vos questions.
Des goodies Debian seront également disponibles !
Nous serons présents au village associatif parmi les nombreux autres stands.
L’idée d’organiser une mini-DebConf à Marseille est née à Toulouse en 2017 : après avoir participé avec plaisir à plusieurs (mini)DebConfs, se lancer dans l’organisation d’un tel évènement est une manière de rendre la pareille et de contribuer à Debian !
Fin 2018, après avoir réuni les personnes motivées, nous avons choisi la date du 25/26 mai 2019 et dimensionner l’évènement pour 50 à 70 personnes en sélectionnant un lieu approprié au centre-ville de Marseille. Je ne vais pas m’attarder ici sur détails de l’organisation (appel à conférences, enregistrement des participants, composition du programme etc.), car nous allons publier bientôt un « Howto Organizing a mini-DebConf » pour partager notre expérience.
Tout a commencé dès le mercredi 22 mai, où la formidable équipe vidéo DebConf s’est réunie pour un sprint de 3 jours pour préparer la couverture de l’événement avec le matériel déjà arrivé et former les membres qui gèreront le matériel pour la mini-DebConf Hambourg.
Une majeure partie des participants sont arrivés dans l’après-midi du vendredi 24 mai. Le bureau d’accueil (Front-Desk) était déjà prêt, et les arrivants ont pu récupérer leur badge et un T-shirt de l’événement. Pour des raisons écologiques, nous avions décidé de minimiser les goodies offerts au participants donc pas de sacs ou papiers superflus, mais un booklet distribué en amont. Si besoin, des goodies Debian (stickers, casquettes, polos, etc.) étaient aussi en vente au Front-Desk.
La soirée de vendredi a débuté avec un mini-CheeseWineBOF avec des denrées locales (fromages, vins, pastis, olives, fruits et légumes) et apportées par des participant(e)s : merci à Valhalla pour fromage italien, ainsi qu’à Urbec et Tzafrir !
La soirée de vendredi s’est poursuivie : pendant que l’équipe vidéo finalisait son installation dans la salle de conférence, les participants ont été invités à une réunion du Linux Users Group de Marseille : une présentation de Florence Devouard, pionnière de Wikipédia, qui est revenue l’historique de Wikipédia/Wikimédia avec de nombreuses anecdotes. La soirée s’est achevée avec une tradition locale : la dégustation de pizzas marseillaises. Le week-end n’est pas encore commencé, et déjà de bons moments sont partagés entre les participants !
Samedi matin, c’était le coup d’envoi officiel de la mini-DebConf ! Ouverture des portes à 8h30 pour le petit déjeuner : cookies fait-maison, café en grains, nous avons proposé durant tout le week-end de la cuisine locale, fait-main et végétarienne. Autre objectif : minimiser les déchets, et dans cette optique nous avons réfléchi à différents dispositifs : couverts en dur, tasses à étiqueter, Ecocups, etc.
75 participants s’étaient inscrits, ce qui correspondait au maximum de la capacité du lieu. Et 73 sont effectivement venus, ce qui est un bel exploit, notamment pour une conférence totalement gratuite. Si l’on compte quelques participants non-inscrits, nous avons été au total plus de 75 participants, soit au-delà de nos espérances !
À 9h45, c’est la conférence d’ouverture ! Jérémy déroule le programme du week-end, remercie les sponsors et rappelle le Code of Conduct, le système d’autorisations pour les photos, etc.
Après une pause-café, c’est Raphaël Hertzog qui revient sur 5 ans du projet Debian LTS (Long Term Support). Il explique l’historique ainsi que le fonctionnement : la gestion des sponsors, le travail réparti entre plusieurs développeurs, l’offre extended LTS, l’infrastructure. Le sujet du financement des contributeurs provoquera plusieurs questions et suscitera un Lightning Talk sur le sujet dimanche matin.
Durant le midi, pendant que l’infatiguable équipe vidéo forme des débutants à ses outils, un déjeuner est servi sous forme de buffet végétalien ou végétarien. Nous sommes fiers d’avoir réussi à offrir une cuisine fait-maison avec des produits frais et locaux, et sans gâchis grâce à une bonne gestion des quantités.
Après le déjeuner, c’est l’heure de la KSP (Key Signing Party) organisée par Benoît. L’occasion pour chacun d’échanger des signatures de clés GPG et de renforcer le réseau de confiance.
Samedi soir, fin de la première journée : tous les participants sont invités à prolonger les échanges à la Cane Bière, un bar proche de la mini-DebConf.
Puis on enchaîne avec une session de 6 Lightning Talks animés par Eda : « kt-update » (Jean-François Brucker), « the Debian Constitution » (Judit Foglszinger), « Elections, Democracy, European Union » (Thomas Koch), les méthodes de vote de Condorcet et du Jugement Majoritaire (Raphaël Hertzog), « encrypt the whole disk with LUKS2 » (Cyril Brulebois), « OMEMO – the big fish in the Debian bowl » (Martin) et « Paye ton Logiciel Libre » (Victor).
Après quelques mots pour clôturer les conférences, c’est déjà l’heure du rangement pour certains, tandis que d’autres en profitent pour faire un mini-DayTrip : descendre la Canebière à pied et embarquer au Vieux Port pour l’archipel du Frioul pour marcher et nager !
Nous remercions les 75 participant(e)s venus du monde entier (Canada, USA, Israël, Angleterre, Allemagne, Espagne, Suisse, Australie, Belgique etc.) ! Nous remercions également la fantastique équipe vidéo qui réalise un travail remarquable et impressionnant de qualité. Nous remercions Debian France qui a organisé l’événement, et les sponsors : Bearstech, Logilab et Evolix. Nous remercions la Maison du Chant de nous avoir mis à disposition les locaux. Nous remercions Valentine et Célia qui ont assuré tous les repas, il y a eu de nombreux compliments. Nous remercions Florence Devouard d’avoir assuré une belle présentation vendredi soir, ainsi que tous les orateurs(ices) de la mini-DebConf. Et je tiens à remercier tous les bénévoles qui ont assuré la préparation et le bon déroulement de l’événement : Tristan, Anaïs, Benoît, Juliette, Ludovic, Jessica, Éric, Quentin F. et Jérémy D. Mention spéciale à Eda, Moussa, Alban et Quentin L. pour leur implication et leur motivation, et à Sab et Jérémy qui se sont plongés avec moi dans cette folle aventure depuis plusieurs mois : you rock guys !
à moins d’acheter des ordinateurs spécifiques, il n’y a plus que ça pour le grand public
Si vous venez d’acheter un ordinateur, choisissez amd64.
L’histoire, avec un grand L
Intel avait conçu une architecture 8086, améliorée successivement jusqu’au 286 (un processeur 16 bits).
Au milieu des années 80, Intel améliore cette architecture qui devient 32 bits (avec les dénominations commerciales 386 puis 486, Pentium, Pentium II, etc.), nommée i386 par Debian, communément appelée x86. Cette architecture est aussi parfois nommée ia32 pour « Intel Architecture 32 bits ». D’autres constructeurs de processeurs comme AMD ou Cyrix concevaient des processeurs compatibles. C’est donc cette même architecture (i386) qui devait être utilisée pour ces processeurs.
Autocollant Intel Pentium 4 (32 bits) comme on en trouvait collé sur des ordinateurs portables au début des années 2000
Puis Intel décida de faire un nouveau processeur, 64 bits, incompatible avec les x86. Associé à HP, une nouvelle gamme de processeur, Itanium, voit le jour en 2001. La dénomination Debian est donc ia64 (« Intel Architecture 64 bits »). C’est un échec commercial, dû à des performances décevantes et l’absence de compatibilité ascendante. Cette gamme sera arrêtée dans l’indifférence générale en 2013.
Parallèlement à Intel, AMD décide d’étendre le processeur x86 pour qu’il fonctionne en 64 bits tout en ayant une compatibilité 32 bits. Cette architecture est souvent appelée x86_64, parfois x64. En 2003, AMD vend l’Athlon 64, premier processeur disponible au public de cette nouvelle architecture. Debian la désigne par le terme amd64. Des accords entre AMD et Intel permettant aussi à Intel de produire cette architecture, Intel a emboîté le pas à AMD et produit aussi des processeurs compatibles amd64. C’est pourquoi les processeurs modernes Intel nécessitent cette architecture lors de l’installation d’un système Debian.
Bien plus récent que le Pentium4, c’est un processeur 64 bits. Les autocollants, c’est bien joli mais pas très informatif.
D’autres architectures moins connues voire complètement oubliées existent
Debian est installable sur de nombreuses autres architectures, mais qui ne sont pas orientées grand public. La seule exception étant peut-être ARM avec les cartes RaspberryPi (cf. wiki).
J’étais donc ce week-end en cours CG (responsables de groupes) pour l’ASVd à Froideville. Je tombe sur une conversation entre Chat et Pélican au sujet du lancement d’une commission IT au niveau cantonal pour fournir des services aux groupes du canton.
On continue la discussion, qui embraie rapidement sur un échange d’idées sur Framasoft, MiData (db.scout.ch) et les différentes initiatives pour fournir des services IT aux groupes scouts du canton.
Pour un petit historique, il y’a déjà eu plusieurs initiatives dans ce sens, mais actuellement, je n’ai pas connaissance d’équipes actives ou fonctionnelles pour ça:
Pour l’ASVd:
un bénévole s’occupe des services cloud (NextCloud), email, listes et site Internet (WordPress).
des groupes DropBox continuent d’exister.
Pour les groupes:
rien de centralisé, mais différentes initiatives isolées naîssent et meurent (Trello, Mattermost, etc)
Bref. La discussion a finalement tourné autour des idées suivantes:
Un service scout
S’inspirer de ce que fait Framasoft et les collectifs Chatons: décentraliser les services et reprendre le contrôle!
Commencer petit; proposer quelque chose de spécifique aux scouts suisses, voir même scouts vaudois pour commencer.
Tirer profit du bénévolat, mais couvrir tous les frais
Offrir des services « collectifs » (une instance cloud par canton) et « spécifiques » (une instance Mattermost par groupe)
Avoir des ambitions techniques élevées:
uniquement du logiciel libre
automatisation des processus
confiance dans les données (backup)
monitoring des services
intégrations qui font sens
authentification unifiée
reproductibilité du projet
Tout ça est évidemment à discuter, clarifier, raffiner, prioriser avec les premiers intéressés. Mais… Je cherchais un nom, en rapport autant avec le champ lexical des chats (Chatons) et du scoutisme. J’avais d’abord pensé à « gamelle », qui me plaisait bien, mais tous les `.ch` étaient pris. « Veillée », vraiment bien, et veillée.ch est libre; mais il y’aurait confusion avec le même nom sans accent.
En feuilletant mon Livre de la Jungle de poche (non, non, en vrai: https://fr.wikipedia.org/wiki/Le_Livre_de_la_jungle#Les_animaux ), j’ai commencé à parcourir les différents animaux de l’histoire en testant leur disponibilité en .ch . Et c’est là que Mère Louve; Raksha, est apparue libre!
Raksha : la louve grise, également appelée Mère-Louve ou La démone, mère adoptive de Mowgli. Elle le défend lorsque Shere-Khan le réclame à l’entrée de sa tanière.
C’est plutôt un bon nom: les scouts avec une âme de louveteaux reconnaîtront le nom immédiatement, et c’est également un animal qui a des petits par portées, avec un aspect de défense des intérêts des scouts, et un aspect de collectif. Des chatons au louveteaux, on n’est pas très loin!
S’il est impossible d’avoir un terminal en appuyant simultanément sur ctrl+alt+F6 , il est possible de paramétrer Grub pour démarrer Linux avec un environnement multi-utilisateur mais sans interface graphique (runlevel 3) :
Lorsque le menu de Grub s’affiche, appuyer sur e pour modifier temporairement la configuration.
Puis ajouter 3 à la fin de la ligne : linux /boot/vmlinuz-… root=UUID=12345678-… ro quiet 3
Puis appuyer sur la/les touches indiquées par Grub pour exécuter cette entrée.
J’ai trouvé plusieurs explications indiquant d’utiliser text à la place de 3 mais ça ne fonctionne pas avec la version avec laquelle j’ai subi ce problème (2.02+dfsg1-6).
Imaginons qu’Airgan, une plateforme communautaire payante de location et de réservation d’organes, veuille améliorer le suivi des visites sur son site web. Matomo est une réponse possible à ce besoin.
Matomo, anciennement Piwik, est un service web pour collecter des statistiques de visites. L’entreprise propose une version libre, auto-hébergeable et une version hébergée uniquement par Matomo qui inclut des fonctions non disponibles dans la version libre.
Matomo fournit un fichier .deb, permettant d’installer le service facilement sur une machine Debian. Cet article présente quelques éléments à prendre en compte.
Le changement de nom de Piwik à Matomo date de Janvier 2018. Tout n’a pas été transféré et la documentation ou les variables laissent parfois encore apparaître l’ancien nom.
Installation du paquet piwik
Le paquet n’est pas inclus dans la distribution mais est fourni dans un dépôt tiers géré par Matomo.
La documentation pour installer le paquet fourni par Matomo est disponible à http://debian.piwik.org/. Il suffit de la suivre.
Installation du paquet php-mbstring
Le fonctionnement du service nécessite que le paquet php-mbstring soit installé. Si ce n’est pas le cas, une erreur lors de la configuration de Matomo (dans quelques étapes, patientez !) sera affichée :
Une pull-request sur Github a été faite pour ajouter php-mbstring aux dépendances. Cette étape ne sera peut-être plus nécessaire dans la prochaine version ?
Configuration du service web
Le paquet ne dépend pas d’un serveur web en particulier. Le code d’example suivant suppose que c’est Apache2 qui est installé. N’importe quel autre serveur web fonctionnerait aussi.
<VirtualHost 19.84.19.84:80>
ServerName matomo.airgan.tld
# ce sera bien pratique quand on aura des problèmes
ErrorLog /srv/airgan/logs/matomo-http-error.log
CustomLog /srv/airgan/logs/matomo-http-access.log combined
LogLevel info
# les deux lignes importantes
DocumentRoot /usr/share/piwik
DirectoryIndex index.php
</VirtualHost>
Ensuite, il faut activer le virtualhost : sudo a2ensite matomo.conf
sudo systemctl reload apache2
Ajouter un utilisateur pour la base de données
Un serveur de base de données MySQL ou MariaDB doit être installé. Ensuite, il faut se connecter sur ce serveur pour créer un utilisateur qui pourra créer la base de données et les tables nécessaires lors de la configuration de Matomo (c’est juste après cette étape, vous avez bien fait de patienter !).
#Créer un utilisateur nommé matomo :
CREATE USER matomo@'localhost';
SET PASSWORD FOR matomo@'localhost' = PASSWORD('secret');
#Lui donner les droits pour créer la base de données nécessaire au service :
GRANT CREATE, ALTER, SELECT, INSERT, UPDATE, DELETE, DROP, CREATE TEMPORARY TABLES on *.* to matomo@'localhost';
Configurer le service Matomo
Avec un navigateur web, allez sur le domaine paramétré dans la configuration du serveur web (matomo.airgan.tld dans notre exemple). Il suffit de suivre les étapes de l’interface pour finir l’installation. Elle correspond à l’étape « The 5-minute Matomo Installation » sur https://matomo.org/docs/installation/.
Une fois cette étape terminée, l’installtion est terminée et aller sur le domaine permet de voir l’interface de connexion pour accéder aux statistiques de visite.
Versions utilisées
L’installation ayant servie à écrire l’article a été faite sur Debian GNU/Linux 9.3 (stretch) avec les versions suivantes des paquets :
apache2
2.4.25-3+deb9u4
mariadb-server
10.1.26-0+deb9u1
piwik
3.2.1-1
Dans le futur, il est possible que la livraison des organes se fasse à vélo. À étudier dans un prochain business plan.
Vu près de l'entrée d'un jardin public, celui de Brimborion, de mémoire :
Panneau rond avec une large bordure verte et un vélo noir au
milieu
Alors, dans ce parc, le vélo est-il autorisé, interdit, recommandé,
obligatoire ? (Rayez les mentions inutiles.)
C'est interdit, évidemment, mais modifier ainsi la couleur d'un
panneau standard est une très mauvaise idée. Et la raison pour
laquelle cette erreur a été commise, à savoir mieux s'assortir avec la
couleur de l'environnement, est parfaitement stupide. Service des parcs
de Sèvres, changez-moi ça tout de suite !
Pour rappel:
« Let's Encrypt (abrégé LE) est une autorité de certification lancée le 3 décembre 2015 (Bêta Version Publique). Cette autorité fournit des certificats gratuits X.509 pour le protocole cryptographique TLS au moyen d’un processus automatisé destiné à se passer du processus complexe actuel impliquant la création manuelle, la validation, la signature, l’installation et le renouvellement des certificats pour la sécurisation des sites internet. » Contenu soumis à la licence CC-BY-SA 3.0. Source : Article Let's Encrypt de Wikipédia en français (auteurs ).
Puis, j'ai suivi les instructions (en anglais) pour utiliser l'authentification avec un serveur web autonome (standalone). Cela autorise certbot à lancer son propre serveur web, le temps de créer le certificat. nginx ne doit donc pas fonctionner le temps de créer le certificat (quelques secondes dans mon cas), c'est le but de la première commande. Pour le relancer, j'ai utilisé la commande suivante:
root@server ~# systemctl start nginx.service
Configuration de nginx
Pour utiliser la configuration ci-dessous, j'ai d'abord créé une clé Diffie-Hellman comme indiqué par SSL Labs:
Voici le fichier /etc/nginx/sites-available/www.fosforito.fr.conf que j'utilise avec la commande root@server ~# ln -s /etc/nginx/sites-available/www.fosforito.fr.conf /etc/nginx/sites-enabled/www.fosforito.fr.conf:
Une fois tout cela mis en place, je teste avec SSL Labs et je vois que ce site obtient un A, ce qui me va bien.
Mise à jour du certificat
Le paquet certbot met en place une tâche planifiée pour mettre à jour automatiquement le(s) certificat(s) Let's Encrypt ! présent(s) sur le serveur. Malheureusement, pour l'instant, cela ne fonctionne que pour le serveur web apache (paquet apache2 dans Debian).
Pour nginx, j'ai simplement modifié la tâche planifiée, dans le fichier /etc/cron.d/certbot, pour arrêter le serveur web avant le renouvellement de certificat et le relancer après. Voici le fichier au complet (notez les options pre-hook et post-hook):
# /etc/cron.d/certbot: crontab entries for the certbot package
#
# Upstream recommends attempting renewal twice a day
#
# Eventually, this will be an opportunity to validate certificates
# haven't been revoked, etc. Renewal will only occur if expiration
# is within 30 days.
SHELL=/bin/sh
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
0 */12 * * * root test -x /usr/bin/certbot && perl -e 'sleep int(rand(3600))' && certbot -q renew --pre-hook "service nginx stop" --post-hook "service ngnix start"
Récapitulatifs
Mise en place du certificat pour nginx
Arrêter nginx
Créer le certificat Let's Encrypt !
Créer le groupe Diffie-Hellman
Mettre en place la configuration du site web
Relancer nginx
Renouvellement du(des) certificat(s)
Ajouter les options pre-hook et post-hook à la tâche plannifiée.
À voir le tracé de certaines voies cyclables, ceux qui les
conçoivent ne sont pas toujours conscients qu'un cycliste se déplace
avec une vitesse de l'ordre de 20 km/h. Ce genre d'aménagement,
qui serait impensable pour une route normale :
Au top, braquez et serrez le frein à main. Attention… TOP ! ;-)
… ce genre d'aménagement donc, est tout aussi invraisemblable pour une voie cyclable :
Au top, tournez votre guidon à 90°. Attention… TOP ! ;-)
Un cycliste ne peut pas tourner sur place à angle droit. Au mieux, on
peut essayer de s'en approcher, mais ces virages à rayon de courbure
nul sont pénibles et toujours dangereux, parce que cela implique :
de freiner brutalement — et paf, le cycliste qui arrive derrière
et qui n'a pas remarqué cette anomalie du tracé ;
de tourner avec un angle déraisonnable — et zip, le cycliste sur
route mouillée ou jonchée de gravier ou de feuilles
mortes.
Mesdames, Messieurs les responsables des aménagements de voirie, pour
éviter ce genre d'erreur de conception, ce n'est pas compliqué : lorsque
vous tracez une voie cyclable, essayez d'imaginer qu'il s'agit d'une
route normale, en plus petit. Vous n'iriez tout de même pas mettre une
chicane à angle droit sur une route normale ? Eh bien, sur une piste
cyclable, c'est pareil, si vous devez mettre une chicane, prévoyez un
rayon de courbure raisonnable. Sans cela, dans le meilleur cas, les
cyclistes ne respecteront pas votre aménagement inapproprié, et dans le
pire des cas vous ramasserez des cyclistes et des piétons
accidentés, direction l'hôpital le plus proche.
« Let's Encrypt (abrégé LE) est une autorité de certification lancée le 3 décembre 2015 (Bêta Version Publique). Cette autorité fournit des certificats gratuits X.509 pour le protocole cryptographique TLS au moyen d'un processus automatisé destiné à se passer du processus complexe actuel impliquant la création manuelle, la validation, la signature, l'installation et le renouvellement des certificats pour la sécurisation des sites internet1. » (Contenu soumis à la licence CC-BY-SA 3.0. Source : Article Let's Encrypt de Wikipédia en français (auteurs) )
Bref, c'est bien pratique pour faire du HTTPS (entre autres) et on peut automatiser le renouvellement des certificats. Il y a plusieurs années, j'aurais fait un cron, mais comme j'ai appris que systemd pouvait gérer des tâches répétitives, je me suis dit que c'était l'occasion de m'y mettre !
Comment on fait ?
Voici les étapes suivies, détaillées ci-dessous puis quelques documents qui m'ont permis de le faire, sans compter le conseil d'un ami: « T'as qu'à faire un timer ! » :
Copier certbot sur le serveur, logiciel (libre, non-copyleft) de gestion des certificats de Let's Encrypt
Créer un script pour renouveler les certificats avec certbot
Créer une minuterie (timer) systemd pour lancer le service à intervalles réguliers
Enfin, activer et lancer la minuterie puis vérifier que ça fonctionne.
1. Copier certbot sur le serveur
Je le copie dans le dossier /opt du serveur:
root@serveur:~# cd /opt/ && git clone https://github.com/certbot/certbot […]
2. Créer le script pour utiliser certbot
Le script se nomme certbot-renew, il est créé dans /opt/certbot/, au même endroit que certbot. Créez aussi le dossier pour les journaux avec la commande mkdir /var/log/letsencrypt/.
Si vous utilisez le serveur web apache, changez le service que systemd doit arrêter et redémarrer, en gras dans le code ci-dessous:
C'est cette minuterie qui va lancer le service créé à l'étape précédente. Notez que la valeur daily pour OnCalendar lance le service à minuit. Comme le serveur était programmé pour faire d'autres choses à minuit, j'ai utilisé un autre moment. ^^
Il ne reste plus qu'à activer cette minuterie pour qu'elle soit lancée à chaque démarrage du serveur: systemctl enable certbot-renew.timer
Pour éviter un redémarrage, la minuterie peut être lancée manuellement: systemctl start certbot-renew.timer
Pour vérifier que tout fonctionne bien le service peut aussi être lancé manuellement: systemctl start certbot-renew.service. Vérifiez alors les journaux pour voir si tout s'est bien déroulé.
Voici donc comment j'ai procédé, il doit exister bien d'autres façons de faire, n'hésitez-pas à m'en faire part et/ou à améliorer ce que je présente ici.
Après avoir acheté un beau coffret de la trilogie cinématographique
Le Hobbit, j'ai eu la surprise d'un trouver des instructions
pour « récupérer une copie numérique » pour regarder ces films « sur
tous mes écrans » grâce à un machin appelé UltraViolet. Les
instructions indiquées sont les suivantes :
S'agissant d'un machin développé par la MAFIAA, je pouvais déjà
prédire le résultat, mais par acquit de conscience, j'ai tout de
même essayé, avec un navigateur Web Firefox sous Debian
GNU/Linux, plugin Flash installé et à jour, JavaScript et
cookies activés sans restriction. Après tout, il est bien
indiqué sur le papier que c'est censé marcher « sur tous mes
écrans », avec de beaux petits schémas représentant un
téléphone, une tablette, un ordinateur portable et un
téléviseur.
Étape 1, Warner Bros
Deux étapes, on pourrait difficilement faire plus simple ! Sauf
qu'évidemment, ça se complique. Sur la page UltraViolet de Warner Bros,
il n'y a pas d'endroit où saisir un code ; au lieu de cela, il est
proposé deux sites partenaires où on doit pouvoir l'entrer : Nolim films et Flixter.
Étape 1, deuxième partie, premier essai, Nolim films
Lorsque j'ai essayé, hier, la page de Nolim films affichait seulement
« chargement en cours ». Après quelques minutes, j'ai donc renoncé et
été voir chez Flixter.
Étape 1, deuxième partie, deuxième essai, Flixter
Côté Flixter, ça commence bien, on arrive sur un site en anglais. Une
fois passé en français, il y a un bouton pour « Utiliser un code ». On
tape le code et… ça dit qu'il n'y a aucun résultat. En fait, il faut
saisir le titre du film, et ensuite seulement, saisir le code
d'activation.
Étape 2, (essayer de) regarder ou télécharger le film
Il faut alors créer un compte, qui demande de fournir des
renseignements personnels, c'est à dire des informations qui ne
devraient certainement pas les concerner : pour regarder un film qu'on a
acheté, il est anormal de devoir donner son nom, prénom et date de
naissance. Personnellement, j'ai renseigné mon nom, mais une date de
naissance bidon.
Enfin, on peut regarder son film. Enfin, essayer, parce que ça ne
marche pas : ça lance une page avec Flash, qui affiche… du noir, puis un
indicateur de chargement, et qui finit par planter le lecteur Flash.
On peut aussi télécharger son film avec un logiciel propriétaire
proposé pour cela. Il est prévu pour Windows, et ne s'installe pas sous
Wine.
Étape 3, ripper son DVD
Comme prédit, ça ne fonctionne pas. Il est donc temps de faire un peu
chauffer mon processeur pour ripper mes DVD : ça au moins, ça
fonctionne, et sans la moindre restriction. Autrement, ces flims doivent
également être disponibles sur les réseaux de contrefaçon :
contrairement à l'UltraTropLaid, ça aussi, ça fonctionne.
Il se trouve que j'ai déménagé récemment. J'en ai profité pour demander un abonnement Internet à l'association de la Fédération FDN de mon coin: Rézine. J'ai donc mis ma brique Internet chez quelqu'un, le temps que l'accès Internet soit en place.
Le problème
Quand j'ai connecté la brique depuis un autre accès Internet, plus rien n'a fonctionné : pas de nouvelles de la brique sur Internet, ni sur le réseau local !
La solution
Note pour les avocats: cette solution a fonctionné chez moi, mais il y a un risque de perdre des données. Rien ne garanti qu'elle fonctionnera chez vous ! Je ne peux pas être tenu pour responsable des actions que vous faites. En cas de doute, demandez de l'aide au membre FFDN le plus proche de chez vous !
"Malheureusement", j'ai un modèle de brique datant de juillet 2015 (avec la migration du blog sur la brique fin 2015). Et une fois fonctionnelle, je ne me suis pas occupé de son entretien: ne pas toucher à quelque chose qui fonctionne me semble un bon conseil à suivre en informatique.
Mais là, je n'avais pas vu qu'il y avait des erreurs sur le disque. Ces erreurs n'ont été gênantes qu'une fois la brique éteinte et rallumée. J'ai donc pris le disque dur de la brique (la carte microSD) et je l'ai mis dans mon PC.
Puis, avec la commande lsblk j'ai vu que la partition de ce disque était /dev/sdc1; j'ai alors pu lancer une vérification du disque avec la commande suivante:
# fsck /dev/sdc1
[…là, ça défile et des fois ça pose des questions…]
Quand la question était posée de corriger les erreurs, j'ai répondu oui. Une fois toutes les erreurs corrigées, j'ai relancé la commande pour vérifier qu'il n'y avait plus d'erreur:
C'est alors, plein d'espoir que j'ai remis le disque dur dans la brique pour la brancher et l'allumer: ça marchait à nouveau !
Deuxième problème
Tout content que la brique refonctionne, j'ai payé un coup à boire à la personne qui l'héberge et je suis rentré chez moi. C'est avec un peu de déception que j'ai réalisé le lendemain que la brique ne fonctionnait plus ! :'-(
Ce deuxième problème est aussi lié au fait que j'ai mis en place ma brique en juillet 2015: à partir du moment où l'application vpnclient mettait en place le tunnel chiffré, la brique n'avait plus accès aux DNS (dont on parle dans cette superbe conférence) !
Après demande d'information à mon fournisseur de tunnels, c'est normal pour pleins de raisons diffèrentes, bref je dois utiliser leur DNS.
Deuxième solution
Une fois le problème identifié, la solution n'est pas loin ! Ici, j'ai mis à jour l'application vpnclient et le tour était joué: la dernière version de cette application prends en compte les DNS ! \o/
Je peux donc maintenant bloguer à nouveau, par exemple pour indiquer comment j'ai déplacé ma brique !
Prochaines étapes: mise en place de sauvegardes… Stay tuned for more info
Dans les années 2000, la RATP et la SNCF on progressivement imposé le
remplacement des tickets de papier anonymes par des cartes à puce
nommées Navigo, pour les utilisateurs d'abonnements. Le problème, c'est
que ces cartes à puces étaient nominatives, et que dans un pays libre,
« aller et venir librement, anonymement, est l’une des libertés
fondamentales. » La CNIL a donc imposé la création d'une carte Navigo
anonyme.
L'histoire bégaie un peu. Dans les années qui viennent, sous la
pression de l'État, les opérateurs de titres restaurant vont
progressivement imposer le remplacement des titres de papier anonymes
par des cartes à puce, qui permettent un plus grand contrôle des usages,
afin d'en limiter les utilisations détournées. Le problème, c'est que
ces cartes à puce sont nominatives, et que dans un pays libre, se
nourrir, et plus généralement consommer librement, anonymement, est
l'une des libertés fondamentales. La CNIL devrait donc imposer la
création de cartes restaurant anonymes.
C'est possible
Les opérateurs de titres restaurant objecteront peut-être que c'est
techniquement impossible. Pour les aider ainsi que la CNIL, voici une
description d'un système qui rendrait possible l'utilisation de cartes
restaurant anonymes. Comme pour les cartes de transport, choisir
l'anonymat peut impliquer de renoncer à certains avantages.
L'entreprise distribuant des titres restaurant à ses salariés dispose
d'un stock de quelques cartes anonymes, seulement identifiées par leur
numéro. Comme toute carte restaurant, chacune est associée à un compte
initialement vide.
Lorsqu'un salarié demandé à disposer d'une carte
anonyme, l'entreprise lui fournit une de ces cartes. Elle
peut noter et transmettre à l'opérateur le fait que cette carte est
maintenant attribuée, mais a interdiction de relever le nom du salarié
qui l'utilise. Si le salarié disposait déjà d'une carte nominative, son
numéro doit être relevé afin de cesser d'alimenter le compte
correspondant, ce qui peut être traité de la même façon qu'un retrait de
l'offre de titres restaurant. Évidemment, l'entreprise a interdiction de
tenter de dissuader les salariés de choisir l'anonymat, et de pénaliser
ceux qui feraient ce choix.
Chaque mois, lors de la distribution des titres
restaurant, le salarié utilisateur d'une carte anonyme se
présente en personne, comme cela se fait pour des titres en papier. Le
responsable approvisionne le compte correspondant au numéro indiqué sur
la carte, et note sur un registre séparé que ce salarié a bien bénéficié
de la distribution. L'entreprise a interdiction de noter sur ce
registre le numéro de la carte créditée, et, d'une façon générale, de
noter ou de transmettre tout ce qui pourrait permettre d'associer les
noms des salariés avec les numéros des cartes anonymes. Encore une fois,
l'entreprise a interdiction de pénaliser les salariés qui se présentent
pour une distribution anonyme.
Le salarié utilise sa carte restaurant de façon
normale pour régler ses consommations et achats éligibles
dans les conditions prévues. Les restaurateurs de enseignes acceptant
les paiements par carte restaurant ont interdiction de pénaliser les
utilisateurs de cartes anonymes. Seules les fonctionnalités annexes de
gestion peuvent être affectées par le caractère anonyme de la carte :
ainsi, en cas de perte, l'opposition sur cette carte ne pourra pas être
effectuée avec le seul nom du bénéficiaire, mais nécessitera la
connaissance de son numéro, faute de quoi elle ne pourra être réalisé,
et le crédit restant devra être considéré comme non récupérable. De
telles restrictions doivent être justifiées par une raison technique :
ainsi, il ne serait pas admissible de restreindre une opération de
promotion chez un restaurateur partenaire aux seuls titulaires de cartes
nominatives.
La Gare de Lyon est une grande gare parisienne, qui est desservie à
la fois par le réseau régional et par plusieurs grandes lignes
nationales. On y trouve donc :
des riverains, qui habitent ou travaillent près de la gare ;
des usagers quotidiens ;
des voyageurs occasionnels, qui partent ou reviennent par
exemple de week-end ou de vacances en province.
Le parking Méditerranée, opéré par la SAEMES, est situé sous la gare
de Lyon, et accueille le même type de clients :
des usagers quotidiens, qui y parquent leur véhicule tous les
jours ou toutes les nuits ;
des voyageurs occasionnels, qui parquent ponctuellement leur
véhicule pour quelques jours, voire quelques semaines.
Cet usage est indépendant du type de véhicule, qu'il s'agisse d'une
voiture, d'une moto ou d'une bicyclette.
Théoriquement, un accès vélo
Sur sa page Web, le parking
Méditerranée - Gare de Lyon affiche un joli logo vélo, qui
suggère la possibilité d'y garer sa bicyclette (qu'est-ce que ça
pourrait bien vouloir dire d'autre ?).
De surprise en surprise
La réalité est toute autre. Le voyageur qui arrive à vélo au parking
Méditerranée va de surprise en surprise (et de pire en pire) :
L'espace vélo n'est pas indiqué, les panneaux donnant
seulement le choix entre l'espace voiture et l'espace moto.
Faute de mieux, autant choisir l'espace moto, c'est ce qui se
fait de plus approchant.
On est censé prendre un ticket, mais la machine n'en
distribue pas aux vélos : on a beau appuyer sur le
bouton prévu pour cela, rien ne sort et la barrière reste
fermée. Qu'à cela ne tienne, un vélo est suffisamment maniable
pour contourner la barrière, mais ça commence mal (et ça va mal
finir, mais pour le moment, on a un train à prendre)…
Une fois arrivé dans l'espace moto, comme on peut s'y attendre,
rien n'est prévu pour fixer des vélos. Peu importe, un
cycliste urbain est de toute façon habitué à stationner comme il
le peut, une barrière fera donc l'affaire, en vérifiant bien
qu'on ne gêne pas le passage ou le stationnement des autres
usagers.
Une fois rentré de voyage, et de retour à la gare de Lyon, on
constate que l'exploitant du parking a enchaîné la
bicyclette, sans un mot d'explication, sans doute parce qu'elle était
mal garée, mais comment pourrait-elle être bien garée puisque l'espace
vélos n'est pas indiqué ?
À l'accueil, l'exploitant exige un paiement pour libérer le
vélo. Pourquoi pas, mais 15 €, c'est un peu cher pour trois
jours de stationnement en occupant zéro emplacement.
Un parking hostile aux vélos
Le parking Méditerranée - Gare de Lyon, qui s'affiche sur le Web avec
un espace vélo, est en réalité hostile à ce type de véhicule.
Le fait d'afficher un espace vélo, qui s'avère en réalité indisponible,
pourrait d'ailleurs relèver de la publicité mensongère.
Suite à cette désagréable expérience, j'ai commencé une
enquête sur
le stationnement vélo dans les parkings publics des grandes gares
parisiennes, dont certains indiquent ainsi disposer d'un espace vélo,
qui peut s'avérer inexistant. Affaire à suivre.
Pour information j’ai découvert ce week-end que Richard Stallman sera présent à la médiathèque de Choisy-le-roi ce samedi 16 avril 2016 à 17h. Pour information des Parisiens indécrottables, c’est en très proche banlieue parisienne :p Comptez par exemple entre 20 et 30 mn depuis le centre de Paris en passant par le RER C pour y arriver.
Bref si vous n’avez jamais vu le monsieur et ses célèbres conférences ou que vous aimeriez une mise-à-jour sur ses positions, c’est l’occasion de le voir. Pour ma part j’y serai.
J’avais depuis quelques temps envie d’écrire un billet de blog au sujet de la soi-disant communauté du Logiciel Libre et le dernier article de Frédéric Bezies , où il regrette le manque de coordination et d’unité de cette communauté, m’a donné la motivation pour finalement expliquer pourquoi tant de gens se désillusionnent quant à « cette » communauté.
« La » communauté du Logiciel Libre, ça n’existe pas
Il est en effet vain dans la plupart des cas de parler de « la » communauté du Logiciel Libre. On peut – et je le fais souvent moi-même – parler de la communauté du Logiciel Libre pour regrouper dans un même sac tous les acteurs touchant de près ou de loin au Logiciel Libre, mais c’est une dénomination vague, peu précise et que l’on ne doit pas employer à tort et à travers.
Et pour cause, car aussi bien d’un point de vue technique que d’un point de vue idéologique, nous, les acteurs de cette soi-disant communauté, sommes profondément et sûrement irrémédiablement divisés.
Les communautés techniques
Rappelons-le car beaucoup de personnes même proches du Logiciel Libre ont tendance à l’oublier. 99% du temps, un projet du Logiciel Libre, c’est au départ un individu isolé non rémunéré qui se motive et prend son courage à deux mains pour écrire du code et porter seul – au moins au début – un projet pour répondre à un besoin existant qui le dérange lui.
Ce faisant, il s’insère dans une communauté technique, celle des outils qu’il utilise pour régler son problème, puis le jour où son projet est prêt, s’il fait le choix de le rendre public, dans une communauté idéologique répondant aux critères que l’on verra au chapitre suivant.
La communauté Python, avec sa propre licence : la PSF, sa propre vision, ses propres objectifs
Au premier niveau, le développeur du Logiciel Libre, c’est donc un utilisateur des outils qui sont mis à disposition par une communauté technique. Il adhère souvent aux idées derrière les outils qu’ils utilisent au quotidien parce qu’il y voit un avantage direct et ressent la cohérence des choix techniques et idéologiques faits par la communauté l’ayant précédé.
Maintenant si on parle de « la » communauté du Logiciel Libre, ça sous-entend que le premier niveau dont je parlais à l’instant se fond dans un deuxième niveau, un niveau plus vaste, plus abstrait, plus global. Donc plus éloigné du développeur au quotidien, touchant des problématiques qu’il ne ressent peut-être pas tous les jours.
Alors qu’au quotidien pour lui, « sa » communauté, c’est par exemple le langage Python et ses membres, pas Perl. Ou la distribution Debian et les buts du projet Debian, pas les systèmes BSD. On se construit donc aussi en opposition à d’autre communautés techniques et idéologiques.
FreeBSD, système d’exploitation et suite d’outils qui privilégient la licence BSD
Les développeurs contribuent donc – le plus souvent dans le cadre de leur temps libre, le plus souvent de façon non-rémunérée, et dans ce domaine seule la motivation permet d’avancer – aux sujets qui nous intéressent et nous motivent au sein d’une communauté technique et idéologique et pas sur les sujets dont « la communauté du Logiciel Libre » aurait besoin.
La diversité des acteurs et de leurs idées, de leurs approches techniques et des solutions qu’ils trouvent au quotidien sont les éléments qui rendent aussi attractif pour beaucoup d’entre nous ce milieu technique et idéologique.
GPL contre BSD/MIT
J’ai évoqué et développé ce point dans l’un de mes précédents articles le danger Github : d’un point de vue idéologique, principalement deux idées du Logiciel Libre coexistent.
La vision incarnée par la licence GPL peut être résumée à une notion fondamentale intégrée par ses défenseurs et ses détracteurs : contaminante. La GPL va nourrir d’elle-même la communauté en réinjectant automatiquement dans le parc logiciel sous GPL tous les dérivés des logiciels eux-mêmes sous GPL. La communauté sert la communauté. Les utilisateurs de la GPL trouvent cohérents de n’utiliser que du Logiciel Libre pour ne pas nourrir l’ennemi , c’est-à-dire le logiciel privateur.
Les licences BSD/MIT sont pour leur part plus permissives, permissives à l’extrême. Rappelons qu’un logiciel dérivé d’un logiciel sous licence BSD/MIT peut être déposé sous une licence propriétaire. Les licences BSD/MIT sont donc non-contaminantes. On a donc la liberté de rendre un logiciel – libre à la base – privateur. Ce qui se fait beaucoup et l’on retrouve les systèmes d’exploitation BSD dans nombre de système d’exploitation propriétaires. voir à ce sujet la liste à couper le souffle des produits commerciaux reposant sur FreeBSD.
Les défenseurs des licences BSD/MIT parlent de liberté réelle face à la GPL, ses détracteurs de la liberté de se tirer une balle dans le pied. Étant donné que les défenseurs de ces licences permissives type BSD/MIT trouvent normal la coexistence du Logiciel Libre et du logiciel privateur, ils utilisent eux-mêmes les deux sans problème, ce qui est cohérent idéologiquement.
Donc au final deux visions très différentes du Logiciel Libre – la GPL plus conquérante, les BSD/MIT plus flexibles – coexistent.
Des communautés constituent le Logiciel Libre
On l’a vu, il serait donc plus précis de parler des communautés qui constituent le Logiciel Libre. Elles sont à la fois techniques et idéologiques et apportent des outils concrets à leurs membres. Elles se définissent par rapport à ce qu’elles construisent, à leurs contributions, mais aussi par opposition aux autres communautés techniques et idéologiques. Il est donc impossible de parler d’une communauté du Logiciel Libre, à moins de la réduire au peu d’idées transverses aux différentes communautés techniques et idéologique la constituant.
J’ai pu remarquer que de nombreux intervenants parlent souvent de la communauté du Logiciel Libre pour parler en fait d’un sous-ensemble de celle-ci, en fait de leur communauté.Par exemple un défenseur de la GPL va parler de la communauté du Logiciel Libre en omettant l’idée de liberté complète derrière les licences BSD/MIT. Ou un idéologue auto-proclamé du Logiciel Libre va déclarer de grandes directions que « le Logiciel Libre » devrait prendre dans une approche top-down alors que, comme nous l’avons vu, tous les contributeurs techniques du Logiciel libre intègrent avant tout une communauté technique et idéologique précise, un sous-ensemble de « la » communauté du Logiciel libre.
Les trolls, une activité prisée des Libristes
Au final il est peut-être rageant de voir au quotidien des projets s’affronter, se troller, de voir des projets réinventer ce qui existent déjà au lieu de l’améliorer. Il semble même incompréhensible de voir des projets entièrement recoder pour des questions de licences ou parfois juste d’ego entre membres de ce qu’on croit être une même communauté. Mais cela tient à une incompréhension de l’organisation et des interactions des projets du Logiciel Libre entre eux.
L’explication tient au fait que le Logiciel Libre est constitué de nombreuses communautés, qui partagent quelques grandes idées communes certes, mais qui portent chacune des solutions techniques, une vision et une identité propres. Elles arrivent à se rejoindre très ponctuellement autour d’un effort commun sur un point extrêmement consensuel, mais il sera tout simplement impossible de les faire toutes et en permanence converger vers des grands objectifs qui bénéficieraient (ou pas) à une vague communauté globale dans laquelle se reconnaîtraient tous les acteurs du Logiciel Libre.
La diversité des communautés qui le compose fait la force du Logiciel Libre, nous partageons quelques grandes idées et nous inventons au quotidien nos propres solutions. Et c’est de cette façon que nous avons avancé jusqu’à aujourd’hui.
Devant le succès de LinuxJobs.fr , le site d’emploi de la communauté du Logiciel Libre et opensource, et la communauté d’utilisateurs qui s’est constitué autour, il était dommage de s’arrêter à l’échange d’offres d’emplois. C’est pourquoi LinuxJobs.fr créé un lieu d’échange et de discussions pour sa communauté, avec des catégories comme les rémunérations, le droit du travail, les questions des jeunes diplômés, des les étudiants ou l’entrepreunariat.
Ce nouveau forum est fièrement propulsé par le nouveau moteur de forums Flarum, un logiciel libre sous licence MIT.
Au plaisir de discuter bientôt avec vous sur le forum de LinuxJobs.fr.
Des voix critiques s’élèvent régulièrement contre les risques encourus par l’utilisation de Github par les projets du Logiciel Libre. Et pourtant l’engouement autour de la forge collaborative de la startup Californienne à l’octocat continue de grandir.
L’octocat, mascotte de Github
Ressentis à tort ou à raison comme simples à utiliser, efficaces à l’utilisation quotidienne, proposant des fonctionnalités pertinentes pour le travail collaboratif en entreprise ou dans le cadre d’un projet de Logiciel Libre, s’interconnectant aujourd’hui à de très nombreux services d’intégration continue, les services offerts par Github ont pris une place considérable dans l’ingénierie logicielle ces dernières années.
Quelles sont ces critiques et sont-elles justifiées ? Nous proposons de les exposer dans un premier temps dans la suite de cet article avant de peser le pour ou contre de leur validité.
1. Points critiques
1.1 La centralisation
L’application Github appartient et est gérée par une entité unique, à savoir Github, inc, société américaine. On comprend donc rapidement qu’une seule société commerciale de droit américain gère l’accessibilité à la majorité des codes sources des applications du Logiciel Libre, ce qui représente un problème pour les groupes utilisant un code source qui devient indisponible, pour une raison politique ou technique.
De plus cette centralisation pose un problème supplémentaire : de par sa taille, ayant atteint une masse critique, elle s’auto-alimente. Les personnes n’utilisant pas Github, volontairement ou non, s’isolent de celles qui l’utilisent, repoussées peu à peu dans une minorité silencieuse. Avec l’effet de mode, on est pas « dans le coup » quand on n’utilise pas Github, phénomène que l’on rencontre également et même devenu typique des réseaux sociaux propriétaires (Facebook, Twitter, Instagram).
1.2 Un logiciel privateur
Lorsque vous interagissez avec Github, vous utilisez un logiciel privateur, dont le code source n’est pas accessible et qui ne fonctionne peut-être pas comme vous le pensez. Cela peut apparaître gênant à plusieurs points de vue. Idéologique tout d’abord, mais peut-être et avant tout pratique. Dans le cas de Github on y pousse du code que nous contrôlons hors de leur interface. On y communique également des informations personnelles (profil, interactions avec Github). Et surtout un outil crucial propriétaire fourni par Github qui s’impose aux projets qui décident de passer chez la société américaine : le gestionnaire de suivi de bugs.
Windows, qui reste le logiciel privateur par excellence, même si d’autres l’ont depuis rejoint
1.3 L’uniformisation
Travailler via l’interface Github est considéré par beaucoup comme simple et intuitif. De très nombreuses sociétés utilisent maintenant Github comme dépôt de sources et il est courant qu’un développeur quittant une société retrouve le cadre de travail des outils Github en travaillant pour une autre société. Cette fréquence de l’utilisation de Github dans l’activité de développeur du Libre aujourd’hui participe à l’uniformisation du cadre de travail dudit développeur.
L’uniforme évoque l’armée, ici l’armée des clones
2. Validité des points critiques
2.1 Les critiques de la centralisation
2.1.1 Taux de disponibilité du service
Comme dit précédemment, Github est aujourd’hui la plus grande concentration de code source du Logiciel Libre. Cela fait de lui une cible privilégiée. Des attaques massives par dénis de service ont eu lieu en mars et août 2015. De même, une panne le 15 décembre 2015 a entraîné l’indisponibilité de 5% des dépôts. Idem le 15 novembre. Et il s’agit des incidents récents déclarés par les équipes de Github elles-mêmes. On peut imaginer un taux d’indisponibilité moyen des services bien supérieur.
2.1.2 Blocage de la construction du Logiciel Libre par réaction en chaîne
Aujourd’hui plusieurs outils de gestion des dépendances comme npm dans le monde javascript, Bundler dans le monde Ruby ou même pip pour le monde Python sont capables d’aller chercher le code source d’une application directement depuis Github. Les projets du Logiciel Libre étant de plus en plus intriqués, dépendants les uns des autres, si l’un des composants de la chaîne de construction vient à manquer, c’est toute la chaîne qui s’arrête.
Un excellent exemple de cet état de fait est la récente affaire du npmgate (voir l’article Du danger d’un acteur non-communautaire dans votre chaîne de production du Logiciel Libre). Github peut très bien demain être mis en demeure par une entreprise de retirer du code source de son dépôt, ce qui pourrait entraîner une réaction en chaîne menant à l’impossibilité de construire de nombreux projets du Logiciel Libre, comme cela vient d’arriver à la communauté Node.js à cause de la société Npm, inc. gérant l’infrastructure de l’installeur automatisé npm.
2.2 Un peu de recul historique : SourceForge
Même si l’ampleur du phénomène n’a pas été la même, il est bon de rappeler que Github n’est pas apparu ex-nihilo et avait un prédécesseur ayant joui en son temps d’un engouement important : SourceForge.
Fortement centralisé, reposant également sur de fortes interactions avec la communauté, SourceForge est un SAAS fortement vieillissant ces dernières années et subit une véritable hémorragie de ses utilisateurs au profit de Github. Ce qui signifie beaucoup d’ennuis pour ceux qui y sont restés. Pour le projet Gimp, il s’agit tout d’abord d’abus publicitaires trompeurs indignes, qui entraînent également le départ du projet VLC , puis l’apparition d’installeurs comprenant des adwares se faisant passer pour l’installeur officiel Windows de Gimp. Et enfin purement et simplement le piratage du compte SourceForge du projet Gimp par… les équipes de SourceForge elle-même.
Nous voyons ici des exemples récents et très concrets des pratiques dont sont capables les sociétés commerciales lorsqu’elles sont sous la pression de leurs actionnaires. D’où la nécessité de bien comprendre l’enjeu représenté par le fait de leur confier une centralisation des données et des échanges ayant de fortes conséquences sur le fonctionnement et les usages de la communauté du Logiciel Libre et opensource.
2.3 Les critiques relatives à utiliser un logiciel privateur
2.3.1 Une communauté, différents rapports au logiciel propriétaire
Cette critique, avant tout idéologique, se heurte à la conception même que chacun des membres de la communauté se fait du Logiciel Libre et opensource, et en particulier d’un critère : contaminant ou non, qu’on résume en général par GPL versus MIT/BSD.
Les défenseurs du Logiciel Libre contaminant vont être gênés d’utiliser un logiciel propriétaire car ce dernier ne devrait pas exister. Il doit être assimilé, pour citer Star Trek, car il est une boîte noire communicante, qui met en danger la vie privée, détourne nos usages à des fins commerciales, gêne ou contraint la liberté de jouir entièrement de ce qu’on a acquis, etc.
Les pendants d’une totale liberté sont moins complexés dans leur utilisation des logiciels privateurs puisqu’ils acceptent l’existence desdits logiciels privateurs au nom d’une liberté sans restriction. Ils acceptent même que le code qu’ils développent aboutissent dans ces logiciels, ce qui arrive bien plus souvent qu’on ne le croit, voir à ce sujet la liste à couper le souffle des produits commerciaux reposant sur FreeBSD. On peut donc voir dans cette aile de la communauté du Logiciel Libre une totale sérénité à utiliser Github. Et ce qui est cohérent vis-à-vis de l’idéologie soutenue. Si vous êtes déjà allé au Fosdem, un coup d’œil dans l’amphithéâtre Janson permet de se rendre compte de la présence massive de portables Apple tournant sous MacOSX.
FreeBSD, principal projet des BSD sous licence BSD
2.3.2 Les pertes de données et obstructions liées à l’usage d’un logiciel privateur
Mais au-delà de cet aspect idéologique pur et pour recentrer sur l’infrastructure de Github elle-même, l’utilisation du gestionnaire de suivi de bugs de Github pose un problème incontournable. Les rapports de bugs sont la mémoire des projets du Logiciel Libre. Il constitue le point d’entrée des nouveaux contributeurs, des demandes de fonctionnalités, des rapports de bugs et donc la mémoire, l’histoire du projet qui ne peut se limiter au code seul. Il est courant de tomber sur des rapports de bugs lorsque vous copiez/collez votre message d’erreur dans un moteur de recherche. Mémoire précieuse non seulement pour le projet lui-même, mais aussi pour ses utilisateurs actuels et à venir.
Github propose d’extraire les rapports de bugs via son API, certes, mais combien de projets anticiperont une éventuelle défaillance de Github ou un retournement de situation arrêtant brusquement le service ? Très peu à mon avis. Et comment migrer vers un nouveau système de suivi de bugs les données fournies par Github ?
L’exemple de l’utilitaire de gestion de listes de choses à faire (TODO list) Astrid, racheté par Yahoo! il y a quelques années reste un très bon exemple de service ayant grandi rapidement, largement utilisé et qui a fermé du jour au lendemain, proposant pendant quelques semaines seulement d’extraire ses données. Et il s’agissait là d’un simple gestionnaire de tâches à faire. Le même problème chez Github serait dramatiquement plus difficile à gérer pour de très nombreux projets, si on leur laisse la possibilité de le gérer. Certes le code reste disponible et pourra continuer de vivre ailleurs, mais la mémoire du projet sera perdue, alors qu’un projet comme Debian approche aujourd’hui les 800000 rapports de bugs. Une vraie mine d’or d’informations sur les problèmes rencontrés, les demandes de fonctionnalités et le suivi de ces demandes. Les développeurs du projet CPython passant chez Github ont anticipé ce problème et ne vont pas utiliser le système de suivi de bugs de Github.
Issues, le suivi de bug propriétaire de Github
Autre perte si Github disparaît ou devient inaccessible : le travail de revue des « push requests » (abrégées par PRs) en cours. Pour les lecteurs qui ne connaîtraient pas cette fonctionnalité de Github, il s’agit d’adresser de cloner le dépôt Github d’un projet, de modifier ce clone pour l’adapter à vos besoins, puis ensuite de proposer vos modifications au dépôt d’origine. Le propriétaire du dépôt d’origine va alors étudier les modifications qui lui ont été proposées et si elles lui conviennent les fusionner à son propre dépôt. Il s’agit donc d’une fonctionnalité très importante offerte de Github, qui propose de réaliser les différentes opérations graphiquement via son interface.
Toutefois le travail de revue des modifications proposées peut être long et il est courant d’avoir, pour un projet qui marche bien, plusieurs PRs en cours. Et il est également courant d’échanger des commentaires via ces PRs et/ou via le système de suivi de bugs propriétaires de Github dont nous avons parlé plus haut.
Le code en lui-même n’est donc pas perdu si Github devient inaccessible (quoique, voire plus bas un cas spécifique), mais le travail de revue matérialisée par les éventuels demandes et commentaires présents dans les PRs et les suivis de bugs associés l’est bien, lui. Rappelons également que Github permet de cloner des projets via son interface web propriétaire, puis d’y apporter toujours via la même interface des modifications et ensuite de générer des PRs sans télécharger aucunement le code sur son poste. Dans ce cas de figure, si Github devient indisponible, la perte du code et du travail en cours est totale.
Enfin certains utilisateurs se servent de Github entre autre comme d’une application de favoris, afin de suivre l’activité de leurs projets préférés en s’abonnant à ces projets par la fonctionnalité « Watch ». Ce travail de réunion de données pour la veille technologique est perdu en cas d’indisponibilité du service Github.
Debian, l’un des principaux projets du Logiciel Libre avec autour de 1000 contributeurs officiels
2.4 L’uniformisation
La communauté du Logiciel Libre oscille sans cesse entre un besoin de normes afin de réduire le travail nécessaire pour l’interopérabilité et l’attrait de la nouveauté, caractérisée par l’intrinsèque besoin de différence vis-à-vis de l’existant.
Github a popularisé l’utilisation de Git, magnifique outil qui aujourd’hui touche des métiers bien différents des programmeurs auxquels il était initialement lié. Peu à peu, tel un rouleau compresseur, Git a pris une place si centrale que considérer l’usage d’un autre gestionnaire de sources est quasiment impossible aujourd’hui, particulièrement en entreprise, malgré l’existence de belles alternatives qui n’ont malheureusement pas le vent en poupe, comme Mercurial.
Un projet de Logiciel Libre qui naît aujourd’hui, c’est un dépôt Git sur Github avec un README.md pour sommairement le décrire. Les autres voies sont totalement ostracisées. Et quelle est la punition pour celui qui désobéit ? Peu ou pas de contributeurs potentiels. Il semble très difficile de pousser aujourd’hui le contributeur potentiel à se lancer dans l’apprentissage d’un nouveau gestionnaire de sources ET une nouvelle forge pour chaque projet auquel on veut contribuer. Un effort que fournissait pourtant tout un chacun il y a quelques années.
Et c’est bien dommage car Github, en proposant une expérience unique et originale à ses utilisateurs, taille à grands coups de machette dans les champs des possibles. Alors oui, sûrement que Git est aujourd’hui le meilleur des système de gestion de versions. Mais ça n’est pas grâce à cette domination sans partage qu’un autre pourra émerger. Et cela permet à Github d’initier à Git les nouveaux arrivants dans le développement à un ensemble de fonctionnalités très restreint, sans commune mesure avec la puissance de l’outil Git lui-même.
3. Centralisation, uniformisation, logiciels privateurs et bientôt… fainéantise ?
Le combat contre la centralisation est une part importante de l’idéologie du Logiciel Libre car elle accroît le pouvoir de ceux qui sont chargés de cette centralisation et qui la contrôlent sur ceux qui la subissent. L’aversion à l’uniformisation née du combat contre les grandes firmes du logiciel souhaitant imposer leur vision fermée et commerciale du monde du logiciel a longtemps nourri la recherche réelle d’innovation et le développement d’alternatives brillantes. Comme nous l’avons décrit, une partie de la communauté du Libre s’est construit en opposition aux logiciels privateurs, les considérant comme dangereux. L’autre partie, sans vouloir leur disparition, a quand même choisi un modèle de développement à l’opposé de celui des logiciels privateurs, en tout cas à l’époque car les deux mondes sont devenus de plus en plus poreux au cours des dernières années.
L’effet Github est donc délétère au point de vue des effets qu’il entraîne : la centralisation, l’uniformisation, l’utilisation de logiciels privateurs comme leur système de gestion de version, au minimum. Mais la récente affaire de la lettre « Cher Github… » met en avant un dernier effet, totalement inattendu de mon point de vue : la fainéantise. Pour les personnes passées à côté de cette affaire, il s’agit d’une lettre de réclamations d’un nombre très important de représentants de différents projets du Logiciel Libre qui réclament à l’équipe de Github d’entendre leurs doléances, apparemment ignorées depuis des années, et d’implémenter de nouvelles fonctionnalités demandées.
Mais depuis quand des projets du Logiciel Libre qui se heurtent depuis des années à un mur tentent-ils de faire pleurer le mur et n’implémentent pas la solution qui leur manquent ? Lorsque Torvald a subi l’affaire Bitkeeper et que l’équipe de développement du noyau Linux n’a plus eu l’autorisation d’utiliser leur gestionnaire de versions, Linus a mis au point Git. Doit-on rappeler que l’impossibilité d’utiliser un outil ou le manque de fonctionnalités d’un programme est le moteur principal de la recherche d’alternative et donc du Logiciel Libre ? Tous les membres de la communauté du Logiciel Libre capable de programmer devrait avoir ce réflexe. Vous n’aimez pas ce qu’offre Github ? Optez pour Gitlab. Vous n’aimez pas Gitlab ? Améliorez-le ou recodez-le.
Logo de Gitlab, une alternative possible à Github
Que l’on soit bien d’accord, je ne dis pas que tout programmeur du Libre qui fait face à un mur doit coder une alternative. En restant réaliste, nous avons tous nos priorités et certains de nous aiment dormir la nuit (moi le premier). Mais lorsqu’on voit 1340 signataires de cette lettre à Github et parmi lesquels des représentants de très grands projets du Logiciel Libre, il me paraît évident que les volontés et l’énergie pour coder une alternative existe. Peut-être d’ailleurs apparaîtra-t-elle suite à cette lettre, ce serait le meilleur dénouement possible à cette affaire.
Finalement, l’utilisation de Github suit cette tendance de massification de l’utilisation d’Internet. Comme aujourd’hui les utilisateurs d’Internet sont aspirés dans des réseaux sociaux massivement centralisés comme Facebook et Twitter, le monde des développeurs suit logiquement cette tendance avec Github. Même si une frange importante des développeurs a été sensibilisée aux dangers de ce type d’organisation privée et centralisée, la communauté entière a été absorbée dans un mouvement de centralisation et d’uniformisation. Le service offert est utile, gratuit ou à un coût correct selon les fonctionnalités désirées, confortable à utiliser et fonctionne la plupart du temps. Pourquoi chercherions-nous plus loin ? Peut-être parce que d’autres en profitent et profitent de nous pendant que nous sommes distraits et installés dans notre confort ? La communauté du Logiciel Libre semble pour le moment bien assoupie.
La récente affaire désormais connue sous le nom de npmgate (voir plus bas si cet événement ne vous dit rien) est encore une illustration à mon sens du danger intrinsèque d’utiliser le produit possédé et/ou contrôlé par un acteur non-communautaire dans sa chaîne de production du Logiciel Libre. J’ai déjà tenté à plusieurs reprises d’avertir mes consœurs et confrères du Logiciel Libre sur ce danger, en particulier au sujet de Github dans mon billet de blog Le danger Github.
L’affaire npmgate
Pour rappel sur cette affaire précise du npmgate, l’entreprise américaine Kik.com a demandé à l’entreprise npm Inc., également société américaine, qui gère le site npmjs.com et l’infrastructure derrière l’installeur automatisé de modules Node.js npm, de renommer un module nommé kik écrit par Azer Koçulu, auteur prolifique de cette communauté. Il se trouve qu’il est également l’auteur d’une fonction left-pad de 11 lignes massivement utilisée comme dépendance dans de très très nombreux logiciels enNode.js. Ce monsieur avait exprimé un refus à la demande de kik.com.
Cette entreprise, qui pour des raisons obscures de droits d’auteur semblait prête à tout pour faire respecter sa stupide demande (elle utilise d’ailleurs elle-même du Logiciel Libre, à savoir au moins jquery, Python, Packer et Jenkins d’après leur blog et en profite au passage pour montrer ainsi sa profonde gratitude à l’égarde de la communauté), s’est donc adressé à npm, inc, qui, effrayée par une éventuelle violation du droit d’auteur, a obtempéré, sûrement pour éviter tout conflit juridique.
Azer Koçulu, profondément énervé d’avoir vu son propre droit d’auteur et sa volonté bafoués, a alors décidé de retirer de la publication sur npmjs.com l’ensemble de ses modules, dont le très utilisé left-pad. Bien que npmjs.com ait apparemment tenté de publier un module avec le même nom, le jeu des dépendances et des différentes versions a provoqué une réaction en chaîne provoquant l’échec de la construction de très nombreux projets.
Sourceforge, Github, npmjs.com et … bientôt ?
Sourceforge, devant un besoin accru de rentabilité et face à la desaffection de ses utilisateurs au profit, on l’imagine, de Github, a commencé à ne plus respecter les prérequis essentiels d’une forge logicielle respectueuse de ses utilisateurs.
J’ai présenté assez exhaustivement les dangers liés à l’utilisation de Github dans une chaîne de production du Logiciel dans mon article de blog le danger Github, à savoir en résumé la centralisation, qui avec de nombreux installeurs automatisés qui vont maintenant directement chercher les différents composants sur Github, si Github vient à retirer une dépendance, il se produira une réaction en chaîne équivalente au npmgate. Et cela n’est qu’une question de temps avant que cela n’arrive.
Autres risques, l’emploi de logiciel propriétaire comme l’outil de suit de bugs de Github issues, la fermeture et la portabilité limitées des données hébergées par eux et l’effet plus insidieux mais de plus en plus réel d’une sorte de fainéantise communautaire, inédite dans notre communauté dans la recherche de solutions libres à des produits propriétaires existants et hégémoniques, sentiment également ressenti par d’autres.
Le danger de l’acteur non-communautaire
Devant la massification des interdépendances entre les différents projets et le développement important du Logiciel Libre, aujourd’hui rejoint par les principaux acteurs hier du logiciel privateur comme Microsoft ou Apple qui aujourd’hui adoptent et tentent de récupérer à leur profit nos usages, il est plus que jamais dangereux de se reposer sur un acteur non-communautaires, à savoir en général une entreprise, dans la chaîne de création de nos logiciels.
C’est un modèle séduisant à bien des égards. Facile, séduisant, en général peu participatif (on cherche à ce que vous soyez un utilisateur content), souvent avec un niveau de service élevé par rapport à ce que peut fournir un projet communautaire naissant, une entreprise investissant dans un nouveau projet, souvent à grand renfort de communication, va tout d’abord apparaître comme une bonne solution.
Il en va malheureusement bien différemment sur le moyen ou long terme comme nous le prouve les exemples suscités. Investir dans la communauté du Logiciel Libre en tant qu’utilisateur et créateur de code assure une solution satisfaisant tous les acteurs et surtout pérenne sur le long terme. Ce que chacun de nous recherche car bien malin qui peut prévoir le succès et la durée de vie qu’aura un nouveau projet logiciel.
Les hauts-parleurs internes du portable HP de mes parents, un dv6000, ne marchaient plus : plus de son sans devoir mettre des enceintes ou un casque :-(
En fait, il semble que ce soit un problème classique, qui semble causé par des nappes de connexion internes deffectueuses.
La réparation n'est pas trop compliquée, si on achète une nappe de remplacement, mais on peut aussi trouver un contournement.
J'ai réussi à échanger les deux nappes qui connectent la carte mère à la partie qui contient les boutons et les hauts-parleurs, au dessus du clavier, et même si maintenant, les boutons de cette rangée supérieure ne marchent plus, ce n'est pas trop grave, car le son est revenu.
J'utilise git-annex pour synchroniser le partage sur le NAS de la FreeBox Revolution, de mes fichiers de musique numérisée (MP3, Ogg), de façon à pouvoir gérer la musique sur mon ordinateur, tout en permettant de la jouer sur la télévision du salon, via l'interface de la freebox. La même procédure doit marcher pour d'autres NAS/set top boxes.
Données du problème :
mettre à jour les fichiers depuis le PC (ligne de commande, interfaces graphiques, numérisation de nouveaux CDs, etc.)
avoir un backup sur un disque de sauvegarde (sur une machine différente de cd PC, en cas de fausse manip, ou du NAS, au cas où la freebox plante).
avoir les fichiers en clair dans l'arborescence du NAS, sous son répertoire prédéfini par la freebox
automatiser la synchronisation et les backups, autant que faire se peut
La procédure est la suivante :
monter sur mon ordi, via CIFS, le disque de la freebox, qu'elle exporte via samba : c'est donc un montage ne supportant pas les liens symboliques : git-annex supporte heuresement le mode "direct" pour les remotes. Ce n'est donc pas une remote réseau, mais une remote locale, dans un répertoire de l'ordi. Appelons-le /mnt/freebox-server dans ce qui suit.
initialiser un dossier de bibliothèque musicale comme étant un repo git-annex :
$ cd /mnt/freebox-server/Musiques
# on clone dans un sous-répertoire pour permettre de gérer des fichiers en dehors ce schéma sur la freebox
$ git clone ~/Musique all
$ cd all
$ git annex init "freebox server"
$ cd ~/Musique
$ git remote add freebox-server /mnt/freebox-server/Musiques/all
# copie des fichiers : long
$ git annex copy --to freebox-server
$ git annex sync
$ cd /mnt/freebox-server/Musiques/all
#$ git remote add laptop
$ git annex sync
Normalement, à l'issue de tout cela, le contenu sur la freebox est synchronisé.
Ensuite, il ne reste qu'à ajouter une remote spéciale rsync pour les backups vers une autre machine, mais ça je vous laisse jouer avec git-annex pour voir comment faire ;)
Disclaimer : Valable pour de l’ext3 sous Linux (utilisable sur d’autres filesystems ou Unix à vos disques et péril)
Vous avez un répertoire rempli à rabord de nombreux fichiers, et il est impossible de connaître sa taille, le lister ou l’effacer sans impact sur la production ?
Voici quelques astuces :
– Avec un “ls -ld” sur le répertoire, vous pouvez estimer grossièrement le nombre de fichiers présents dans un répertoire. En effet, un répertoire vide fait 4 Ko (je simplifie). Et plus il contient de fichiers, plus sa taille va augmenter. Par exemple, un répertoire contenant 2 millions de fichiers pourra faire une taille de 100 Mo (je parle bien de la taille du répertoire et non pas de la taille du contenu). Attention, c’est variable selon la longueur des noms des fichiers. Et prendre garde aussi que ce n’est pas dynamique : si vous videz complètement un répertoire bien rempli, il gardera sa taille volumineuse (d’où l’intérêt de recréer un répertoire qui s’est rempli “par erreur”).
– Pour lister les fichiers du répertoire, utiliser la commande “ls” n’est pas une bonne idée car elle accède à toute la liste avant de l’afficher. Voici comment lister 10 fichiers sans attendre :
perl -le 'opendir DIR, "." or die; $i=0; while ($i<10) { my $f = readdir DIR; print $f; $i++; }; closedir DIR'
Grâce à leurs noms, vous pouvez désormais examiner (ouvrir, connaître sa taille) un échantillon de fichiers contenus dans votre fameux répertoire.
Pour lister l’ensemble des fichiers sans attendre comme “ls” :
perl -le 'opendir DIR, "." or die; print while $_ = readdir DIR; closedir DIR'
– Pour effacer le contenu du répertoire en limitant l’impact sur la production, oubliez “rm -rf” qui va saturer vos I/O disque mais préférez le faire par blocs de N fichiers avec des pauses de quelques secondes ! Voici une commande “conviviale” qui va faire cela par blocs de 300 fichiers avec des pauses de 5 secondes :
EDIT : en complément, on n’oubliera pas que l’on peut aussi gérer la priorité d’ordonnancement des I/O avec la commande ionice
(merci à Sylvain B. de l’avoir souligné)
DebConf est la conférence annuelle des développeurs du projet Debian. Cela permet aux développeurs et contributeurs de Debian d’assister à des présentations techniques, sociales et politiques, mais aussi de se rencontrer et travailler ensemble. Cette année, la 11e DebConf s’est tenue à New York du 1er au 7 août. Evolix a sponsorisé cette conférence et j’étais donc sur place, voici mon résumé de cette semaine.
Premiers pas plutôt festifs le vendredi soir avec le SysAdmin Day dans un bar à Manhattan puis direction Brooklyn pour une Debian Party organisée par NYC Resistor, un collectif local de hackers en électronique à l’origine de MakerBot, une imprimante 3D Open Source. Samedi c’est l’arrivée à Columbia University, l’université américaine qui accueille la DebConf 10. Une bonne partie des participants est hébergée sur le campus universitaire, dans des chambres avec accès haut-débit et une cafétéria à volonté.
C’est donc le dimanche 1er août que commence la DebConf avec des présentations orientées grand public pour cette première journée appelée le “Debian Day”. Un grand message de bienvenue pour un public plus large en ce premier jour, puis enchaînement des présentations. J’ai tout d’abord assisté à une présentation sur le sysadmin par François Marier qui a livré toutes ses astuces et une série de packages intéressants (unattended-upgrades, safe-rm, etckeeper, fcheck, fwknop, etc.). J’ai d’ailleurs pu échanger par la suite avec lui d’autres informations, sachant qu’il travaille dans une boîte similaire à Evolix : Catalyst située en Nouvelle-Zélande ! J’ai ensuite assisté à la présentation de Stefano Zacchiroli, l’actuel leader Debian, qui encourage fortement les développeurs à réaliser des NMU (Non Maintainer Upload), c’est-à-dire la publication d’un package par un autre développeur que celui responsable officiellement. J’ai ensuite poursuivi avec la présentation du Google Summer of Code 2010 de Debian : une présentation générale puis plusieurs “étudiants” expliquent leur projet en cours : Debian-Installer pour OpenMoko, GUI pour aptitude en QT, etc. D’autres présentations ont ensuite suivies, mais j’ai plutôt été découvrir le “hacklab” : une pièce pourvue de multiprises, switches et points d’accès afin de permettre à plusieurs dizaines de personnes de travailler/hacker. Le “Debian Day” a été un franc succès avec plusieurs centaines de participants. En soirée, c’est l’heure du coup d’envoi “officiel” de la DebConf par Gabriella Coleman, l’une des organisatrices de la DebConf 10, qui présente avec humour la semaine à venir, avec un petit retour en images sur les éditions précédentes.
Deuxième jour, on a le droit à un Bits from DPL en direct de la part de Stefano Zacchiroli (au lieu du traditionnel mail). Ensuite, il y a de nombreuses présentations. Durant DebConf, il y en aura plus de 100 au total, réparties dans 3 salles : Davis (avec vidéo), 414 Schapiro et Interschool (avec vidéo). Le choix est parfois difficile ! Pour ma part, j’ai assisté en fin de matinée à la présentation de la structure américaine à but non lucractif SPI : c’est elle qui gère les droits de la marque Debian, mais pas seulement : OpenOffice.org, Drupal, PostgreSQL, Alfresco, etc. de nombreux projets de logiciels libres utilisent cette structure légale ! Dans l’après-midi, c’est Mark Shuttleworth, fondateur d’Ubuntu et CEO de Canonical, qui nous présente le travail réalisé pour améliorer l’interface graphique des netbooks, notamment par l’intermédiaire du projet Ayatana. Puis, Jorge Castro, responsable chez Canonical des relations avec les développeurs extérieurs, parle de la collaboration entre Ubuntu et Debian. On notera que toute une équipe de Canonical est venue à DebConf et que les relations avec Debian semblent devenir plus sereines. Le soir venu, c’est l’heure de Wine&Cheese, un évènement devenu incontournable pour une DebConf : imaginez des centaines de fromages et alcools venus du monde entier (Italie, Allemagne, France, Mexique, Brésil, USA, Taïwan, Pologne, Kazhastan, Espagne, Nouvelle-Zélande, Corse, Vénézuela, Hollande, Marseille, Irlande, Angleterre, Japon, etc. etc.) et plus d’une centaine de développeurs Debian lâchés dessus pendant des heures… le résultat est… indescriptible ! Pour ma part, j’avais apporté un rosé Bandol, des bières La Cagole, du Banon et de la Tapenade… qui n’ont pas fait long feu.
Le quatrième jour, c’est le Day Trip. Il s’agit classiquement d’une journée consacrée à des activités touristiques extérieures. Nous avons été visiter l’église Trinity Church à Manhattan où le drame du 11 septembre 2001 a mis un superbe orgue hors d’usage, remplacé temporairement par un orgue électronique “Powered by Linux”… qui a finalement été conservé en raison de sa qualité. Keith Packard, l’un des gourous de X.org employé chez Intel, a joué quelques minutes sur cet orgue. Ensuite, direction la plage de Coney Island. Puis un match de baseball où Stefano Zacchiroli lancera la première balle du match.
Cinquième jour, on reprend avec un BoF (un BoF=Birds of a Feather est une discussion informelle de groupe) sur la virtualisation où plusieurs personnes témoignent de leurs expériences et connaissances sur le sujet. Pas mal d’informations intéressantes, notamment sur le couple Ganeti/KVM pas mal mis en avant par Iustin Pop, l’un des développeurs de Ganeti employé chez Google. J’y apprends notamment que KVM gère une notion de mémoire partagée et ainsi démarrer une 2e machine virtuelle avec un même OS ne consommerait pas de mémoire supplémentaire sur le système hôte ! Suite des présentations, notamment une portant sur DebConf 12 qui pourrait peut-être se dérouler au Brésil. Et fin de la matinée avec François Marier qui présente le projet Libravatar permettant d’offrir une alternative à Gravatar, l’outil centralisé de gestion des avatars. Ses idées sont de se baser sur les DNS pour répartir les avatars pour chaque noms de domaine. Il a déjà commencé à développer une application en Django pour gérer cela. Suite de la journée avec un BoF sur Lintian (outil de vérification de la conformité des packages Debian) géré par Russ Allbery. Puis j’ai assisté à une présentation de Guido Günther qui a expliqué comment gérer son packaging avec Git et notamment git-buildpackage (très intéressant pour moi car je gère déjà mes packages Debian comme ça). Ensuite, petite pause sportive, car une dizaine de développeurs Debian a été participé à un cross de 5 kms dans le Bronx, avec des résultats honorables !
Septième et dernier jour, encore de nombreuses présentations. J’ai notamment assisté à celle de Philippe Kern, membre de la Release Team, qui a parlé du management de la version stable et de volatile. On notera par exemple qu’on peut désormais corriger des bugs en priorité “Important” dans les points de Release. La suite ce sont des fameux Lightnings Talks, une dizaine de présentations très courtes : une qui suggère d’arrêter complètement d’utiliser les mots de passe, une autre sur le logiciel runit, une autre sur les éclairs (lightnings !) ou encore l’historique en photos des Wine&Cheese Party ! Fun et instructif. Puis c’est l’heure de la conférence de clôture, où l’on remet des prix à ceux qui ont corrigé le plus de bugs mais surtout tous les volontaires sont vivement remerciés et j’en profite pour adresser une nouvelle fois mes remerciements à :
– L’équipe qui a organisé cette DebConf 10 : un travail impressionnant pour un résultat professionnel et communautaire à la fois : on frôle la perfection !
– L’équipe vidéo qui a fait un travail génial et vous pouvez ainsi retrouver l’ensemble des talks en vidéo,
– Les centaines de personnes sympas et passionnées qui contribuent à faire de Debian une distribution de grande qualité… et qui sait évoluer, la preuve avec les sujets abordés lors de cette DebConf !
Petite conclusion de cette semaine intensive, comme vous avez pu le lire : j’ai pu acquérir de nombreuses informations et faire le plein de nouvelles idées, mais aussi avoir des contacts réels avec d’autres développeurs et comprendre encore mieux le fonctionnement “social” de Debian. C’est donc très positif et cela va me permettre d’améliorer mon travail quotidien au sein d’Evolix, mais aussi réfléchir à d’autres projets et me motiver pour contribuer davantage à Debian. Debian rules !
Je ne rappellerais pas toutes les précautions nécessaires (tests préalables, sauvegardes, désactivations des services, etc.) ni la classique question sur “quand faut-il migrer ?”, vous trouverez tout cela dans mes exemples précédents. Je rappelle simplement l’idée de base : prendre les précieuses Release Notes, mettre à jour le fichier sources.list, puis exécuter les commandes aptitude update && aptitude upgradex, puis mettre-à-jour les services les plus critiques via aptitude install <PACKAGE>, et enfin aptitude dist-upgrade && aptitude dist-upgrade (répéter dist-upgrade est souvent nécessaire).
Passons désormais aux différentes remarques sur ces migrations :
– PostgreSQL : on passe de la version 8.1 à 8.3. Notez qu’il s’agit de paquets différents, il est donc possible de garder la version 8.1 en Etch, et d’installer en parallèle la version 8.3, afin de faciliter encore plus la migration. Pour migrer les données, on réalisera un dump avec pg_dumpall qui sera réinjecté dans la nouvelle base. On pourra ensuite adapter le port dans postgresql.conf pour passer la version 8.3 en production.
– phpPgAdmin : avec PostgreSQL 8.3, on ne peut plus se connecter à la table template1 : c’est le comportement par défaut de phpPgAdmin, qu’on devra donc modifier en mettant postgres à la place (pour la variable $conf[‘servers’][0][‘defaultdb’] dans le fichier config.inc.php)
– Apache : la configuration de l’alias /icons/ est déplacé dans le fichier mods-available/alias.conf, il peut donc faire doublon avec la déclaration dans apache2.conf, ce qui sera signalé via le warning suivant : [warn] The Alias directive in /etc/apache2/apache2.conf at line 240 will probably never match because it overlaps an earlier Alias. Commenter les directives dans le fichier apache2.conf résoudra ce petit soucis.
– OpenLDAP : on passe d’une version 2.3 à 2.4, mais le plus marquant pour la migration est que cela force le processus à tourner avec un utilisateur/groupe dédié. Pour diverses raisons (dist-upgrade interrompu par exemple), on pourra rencontrer des soucis plus ou moins alarmants. Ainsi, j’ai pu rencontrer cette erreur : bdb(dc=example,dc=com): PANIC: fatal region error detected; run recovery
bdb_db_open: database “dc=example,dc=com” cannot be opened, err -30978. Restore from backup!
backend_startup_one: bi_db_open failed! (-30978)
slap_startup failed On veillera donc sur l’utilisateur/groupe propriétaire des fichiers dans le répertoire /var/lib/ldap et, au besoin, on ajustera : chown -R openldap:openldap /var/lib/ldap/ Mon conseil : mettre-à-jour le paquet slapd de façon spécifique avant le dist-upgrade
– Postfix : on passe de 2.3 à 2.5. On notera simplement la valeur par défaut de $smtp_line_length_limit characters qui passe à 990, ce qui coupe les lignes trop longues pour se conformer au standard SMTP. Si cela posait problème, on pourrait revenir à l’ancien comportement en positionnant smtp_line_length_limit=0
– SpamAssassin : l’utilisant en stockant la configuration des utilisateurs dans un annuaire LDAP, le daemon spamd s’est mis à râler : cannot use –ldap-config without -u
Le problème sera résolu en ajoutant l’option -u nobody, ce qui fera tourner spamd en tant que nobody (ce qui n’est pas une mauvaise chose, au contraire).
– Amavis : apparemment, lors de la détection d’un virus, le code retourné n’est plus 2.7.1 mais 2.7.0 : 2.7.0 Ok, discarded, id=13735-07 – VIRUS: Eicar-Test-Signature
Rien de bien grave, mais cela a nécessité d’adapter un plugin Nagios pour qu’il attende le bon code de retour.
– Courier-imapd-ssl : après une mise-à-jour gardant mon fichier /etc/courier/imapd-ssl actuel, j’obtenai des erreurs avec certains clients IMAP : couriertls: accept: error:1408F10B:SSL routines:SSL3_GET_RECORD:wrong version number
En regardant de plus près, certaines directives changent dans ce fichier de configuration, et il est donc conseillé de repartir du fichier proposé par Lenny, et d’y apporter ses modifications (souvent, cela se limite à préciser le certificat).
– Horde : si vous utilisez une base de données pour stocker les paramètres ou autres, la paquet php-db (déjà en Recommends: en Etch) est d’autant plus nécessaire, sous peine d’obtenir l’erreur : PHP Fatal error: _init() [<a href=’function.require’>function.require</a>]: Failed opening required ‘DB.php’ (include_path=’/usr/share/horde3/lib:.:/usr/share/php:/usr/share/pear’) in /usr/share/horde3/lib/Horde/DataTree/sql.php on line 1877
– Sympa : on attaque là le cauchemard de mes migrations. À chaque fois, tellement de soucis majeurs et mineurs, que j’ai l’impression d’être le seul à utiliser ce paquet. Voici en vrac tous les soucis rencontrés : les accents dans les descriptions ont sautés (une sorte de double encodage) et cela a nécessité des corrections manuelles, la table logs_table doit être créée à la main (j’utilise Sympa avec PostgreSQL), et enfin une typo surprenante un “GROUP BY” à la place d’un “ORDER BY” (j’ai ouvert le bug #566252 à ce sujet).
– Asterisk : on passe de la version 1.2 à la version 1.4. Lors de la migration, j’ai constaté un bug étrange, le fichier modules.conf qui charge les modules additionnels a disparu. Du coup, sans lui, Asterisk ne charge pas les modules nécessaires (SIP, etc.). Il a donc fallu le restaurer.
– udev : le meilleur ami des sysadmins (ou pas). Si les migrations douloureuses Sarge->Etch sont loin derrière nous, il reste néanmoins quelques blagues. La dernière en date a été un renommage des interfaces réseau : eth0->eth1 et eth1->eth2. Classique mais étonnant, ce genre d’humour est sensé être dépassé grâce aux “persistent rules” qui nomment les interfaces en fonction de l’adresse MAC. À rester vigilant sur ce point avant le redémarrage donc.
Voilà pour les remarques. Vous noterez que je n’ai pas abordé le noyau Linux. C’est parce que pour la majorité de nos serveurs, ils sont gérés de façons spécifiques (au lieu d’utiliser les noyaux officiels Debian). Ainsi, ils restent dans leur version actuelle (2.6.31 à cette heure) pendant la migration. Bien sûr, cela n’empêche pas d’effectuer un redémarrage de la machine suite à la mise-à-jour : cela permet de s’assurer que tout est bien en place et le sera toujours après un éventuel redémarrage d’urgence.
Les packages Debian de Java n’intègrent pas de mécanisme pour faciliter l’utilisation des versions non limitées des JCE (Java Cryptography Extension), utiles pour avoir des fonctions de chiffrement dites « fortes » (#466675). L’idée est de créer des diversions locales pour conserver les versions non limitées, même en cas de mise-à-jour :
# dpkg-divert --divert /usr/share/doc/sun-java6-jre/US_export_policy.jar.ori \
--rename /usr/lib/jvm/java-6-sun-1.6.0.12/jre/lib/security/US_export_policy.jar
Adding `local diversion of /usr/lib/jvm/java-6-sun-1.6.0.12/jre/lib/security/US_export_policy.jar
to /usr/share/doc/sun-java6-jre/US_export_policy.jar.ori'
# dpkg-divert --divert /usr/share/doc/sun-java6-jre/local_policy.jar.ori \
--rename /usr/lib/jvm/java-6-sun-1.6.0.12/jre/lib/security/local_policy.jar
Adding `local diversion of /usr/lib/jvm/java-6-sun-1.6.0.12/jre/lib/security/local_policy.jar
to /usr/share/doc/sun-java6-jre/local_policy.jar.ori'
Attention, bien garder à l’esprit que si une faille de sécurité survient, il faudra mettre à jour manuellement ces fichiers.
J'ai essayé de télédéclarer mes impôts sur le revenu depuis ma Debian (testing) avec iceweazel (plugin Java Sun du paquet sun-java5-plugin).
Tou allait bien jusqu'à la phase finale de signature, où j'obtenais des erreurs de ce genre (dans la console Java) :
java.lang.UnsatisfiedLinkError: Expecting an absolute path of the library: local/.TaoUSign/libjsec.so
at java.lang.Runtime.load0(Runtime.java:767)
at java.lang.System.load(System.java:1005)
at com.dictao.plfm.a.b(Unknown Source)
at signview.b(Unknown Source)
at signview.start(Unknown Source)
at sun.applet.AppletPanel.run(AppletPanel.java:465)
at java.lang.Thread.run(Thread.java:619)
Mais j'ai trouvé le contournement suivant pour que ça passe (après avoir complètement quitté iceweasel) : lancer iceweasel depuis le répertoire contenant libnss3.so, avec LD_LIBRARY_PATH positionnée à "." :
$ cd /usr/lib/iceweasel/
$ LD_LIBRARY_PATH=. iceweasel
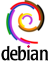









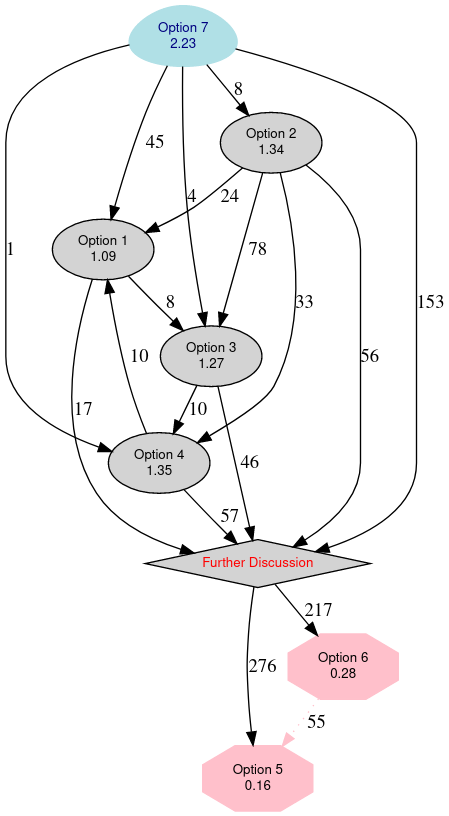











































 Les trolls, une activité prisée des Libristes
Les trolls, une activité prisée des Libristes

 L’octocat, mascotte de Github
L’octocat, mascotte de Github Windows, qui reste le logiciel privateur par excellence, même si d’autres l’ont depuis rejoint
Windows, qui reste le logiciel privateur par excellence, même si d’autres l’ont depuis rejoint L’uniforme évoque l’armée, ici l’armée des clones
L’uniforme évoque l’armée, ici l’armée des clones


 FreeBSD, principal projet des BSD sous licence BSD
FreeBSD, principal projet des BSD sous licence BSD Issues, le suivi de bug propriétaire de Github
Issues, le suivi de bug propriétaire de Github
 Le « lion » devant la cheminée
Le « lion » devant la cheminée
 Premiers pas plutôt festifs le vendredi soir avec le SysAdmin Day dans un bar à Manhattan puis direction Brooklyn pour une Debian Party organisée par
Premiers pas plutôt festifs le vendredi soir avec le SysAdmin Day dans un bar à Manhattan puis direction Brooklyn pour une Debian Party organisée par  C’est donc le dimanche 1er août que commence la DebConf avec des présentations orientées grand public pour cette première journée appelée le “Debian Day”. Un
C’est donc le dimanche 1er août que commence la DebConf avec des présentations orientées grand public pour cette première journée appelée le “Debian Day”. Un  Deuxième jour, on a le droit à un
Deuxième jour, on a le droit à un  Troisième jour et l’on débute par un
Troisième jour et l’on débute par un  Le quatrième jour, c’est le Day Trip. Il s’agit classiquement d’une journée consacrée à des activités touristiques extérieures. Nous avons été visiter l’église Trinity Church à Manhattan où le drame du 11 septembre 2001 a mis un superbe orgue hors d’usage, remplacé temporairement par un orgue électronique “Powered by Linux”… qui a finalement été conservé en raison de sa qualité. Keith Packard, l’un des gourous de X.org employé chez Intel, a joué quelques minutes sur cet orgue. Ensuite, direction la plage de Coney Island. Puis un match de baseball où Stefano Zacchiroli lancera la première balle du match.
Le quatrième jour, c’est le Day Trip. Il s’agit classiquement d’une journée consacrée à des activités touristiques extérieures. Nous avons été visiter l’église Trinity Church à Manhattan où le drame du 11 septembre 2001 a mis un superbe orgue hors d’usage, remplacé temporairement par un orgue électronique “Powered by Linux”… qui a finalement été conservé en raison de sa qualité. Keith Packard, l’un des gourous de X.org employé chez Intel, a joué quelques minutes sur cet orgue. Ensuite, direction la plage de Coney Island. Puis un match de baseball où Stefano Zacchiroli lancera la première balle du match. Cinquième jour, on reprend avec un
Cinquième jour, on reprend avec un  Sixième jour, on débute par
Sixième jour, on débute par  Septième et dernier jour, encore de nombreuses présentations. J’ai notamment assisté à celle de Philippe Kern, membre de la Release Team, qui
Septième et dernier jour, encore de nombreuses présentations. J’ai notamment assisté à celle de Philippe Kern, membre de la Release Team, qui